|
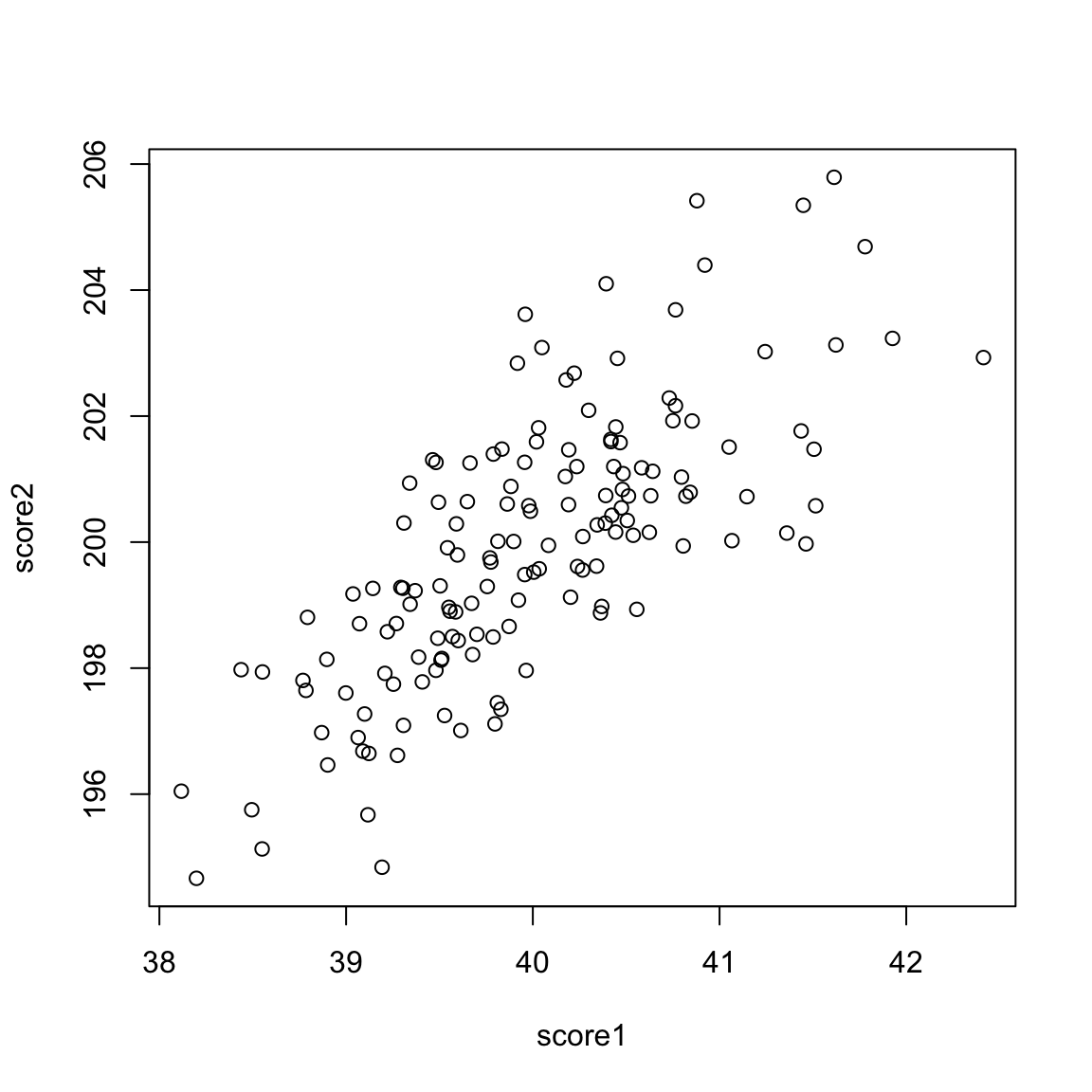
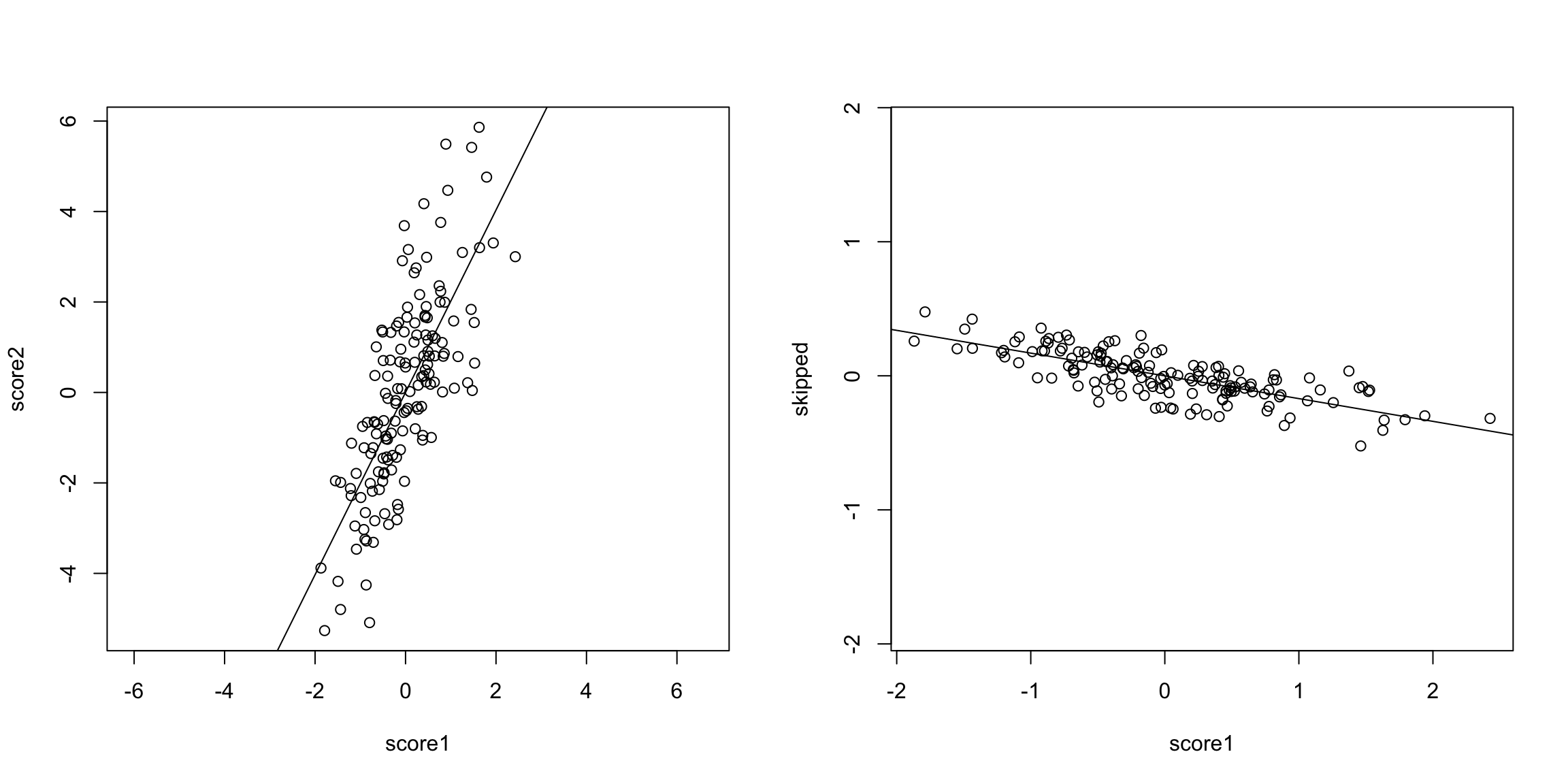
5.4 Principal Components Analysis In looking at both the college data and the gene expression data, it is clear that there is a lot of redundancy in our variables, meaning that several variables are often giving us the same information about the patterns in our observations. We could see this by looking at their correlations, or by seeing their values in a heatmap. For the purposes of illustration, let’s consider a hypothetical situation. Say that you are teaching a course, and there are two exams:
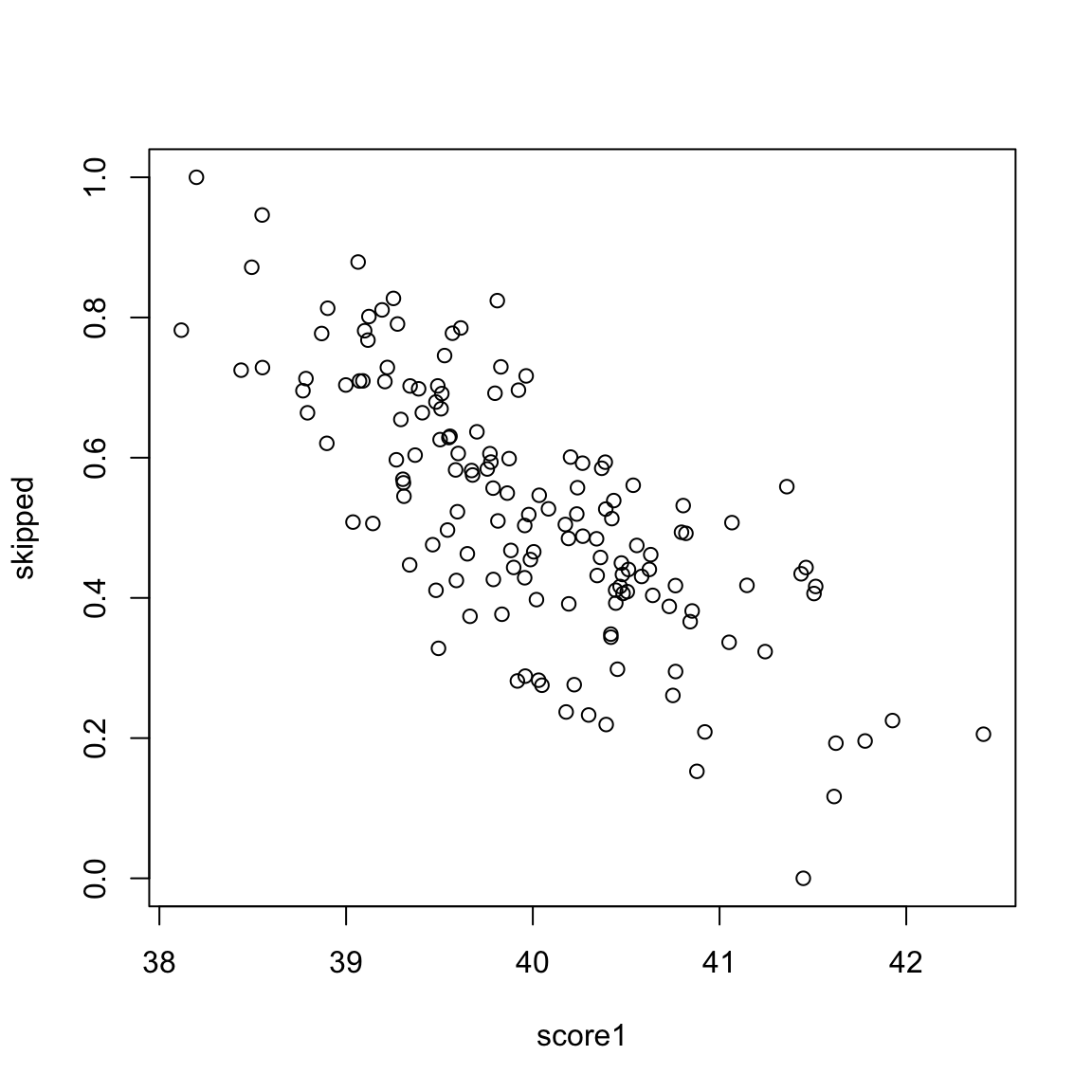
These are clearly pretty redundant information, in the sense that if I know a student has a high score in exam 1, I know they are a top student, and exam 2 gives me that same information. Consider another simulated example. Say the first value is the midterm score of a student, and the next value is the percentage of class and labs the student skipped. These are negatively correlated, but still quite redundant.
The goal of principal components analysis is to reduce your set of variables into the most informative. One way is of course to just manually pick a subset. But which ones? And don’t we do better with more information – we’ve seen that averaging together multiple noisy sources of information gives us a better estimate of the truth than a single one. The same principle should hold for our variables; if the variables are measuring the same underlying principle, then we should do better to use all of the variables. Therefore, rather than picking a subset of the variables, principal components analysis creates new variables from the existing variables. There are two equivalent ways to think about how principal components analysis does this. 5.4.1 Linear combinations of existing variables You want to find a single score for each observation that is a summary of your variables. We will first consider as a running example the simple setting of finding a summary for a student with two grades, but the power is really when you want to find a summary for a lot of variables, like with the college data or the breast cancer data.
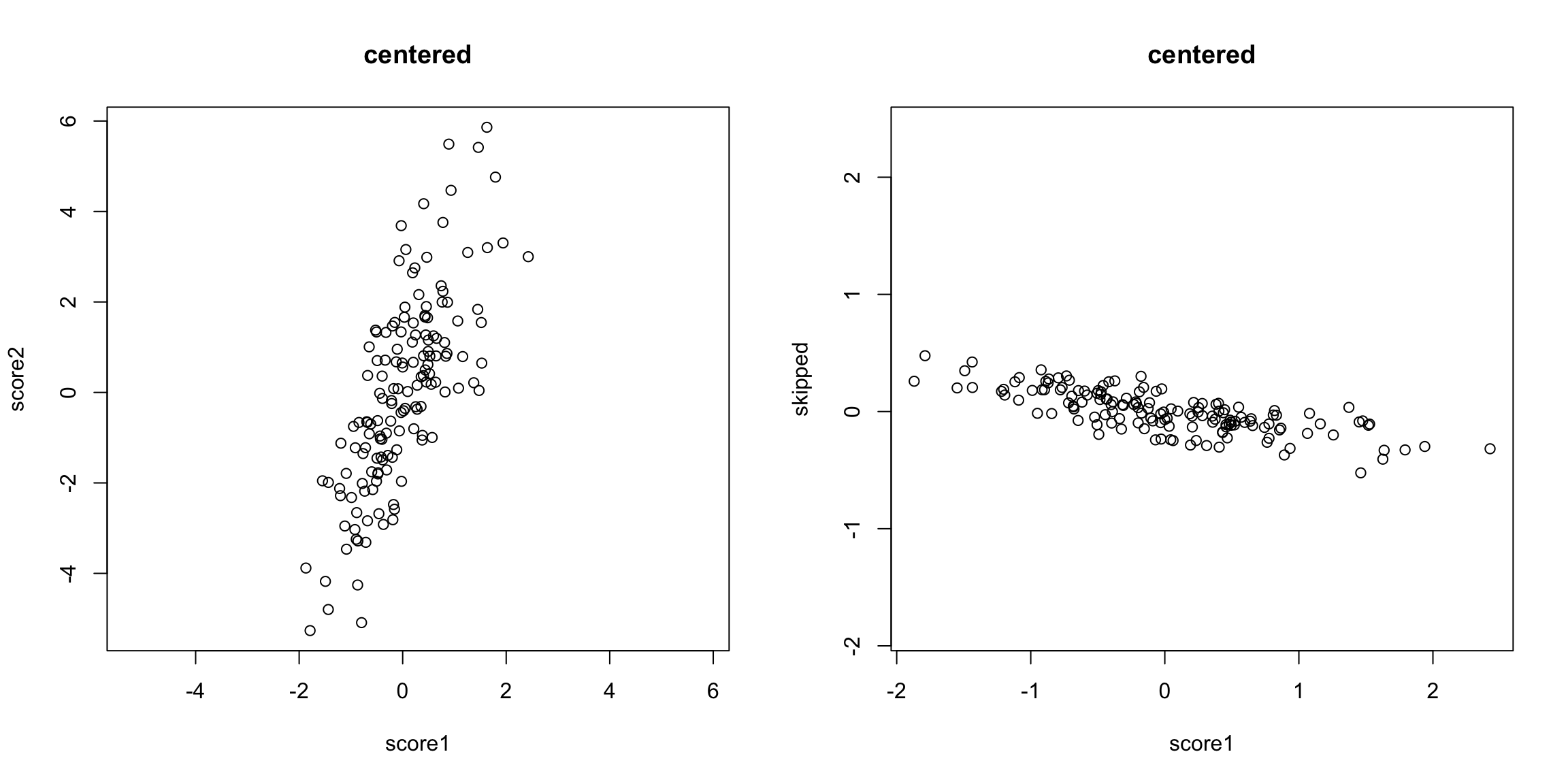
What is the problem with taking the mean of our two exam scores? Let’s assume we make them have the same mean:
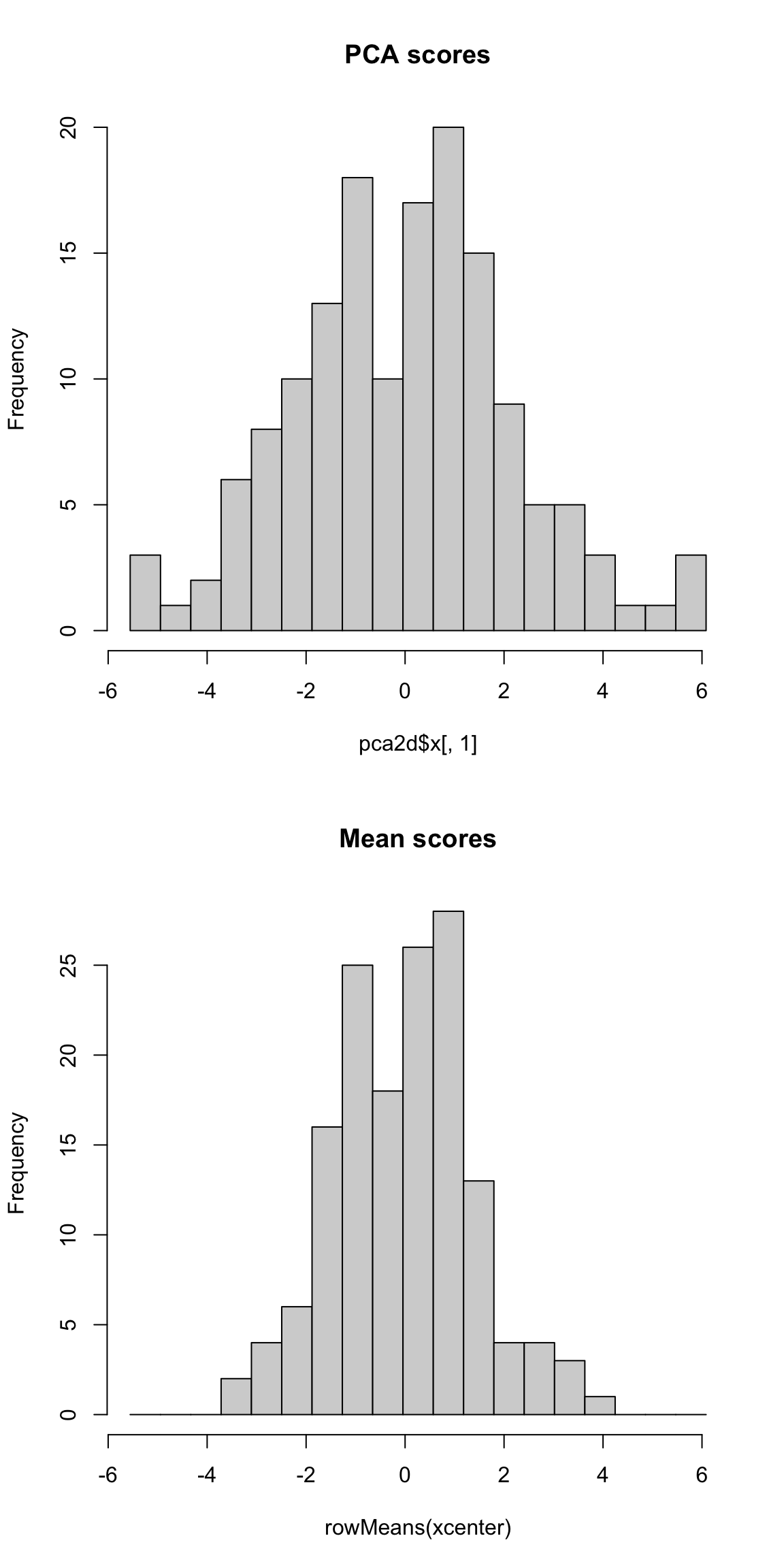
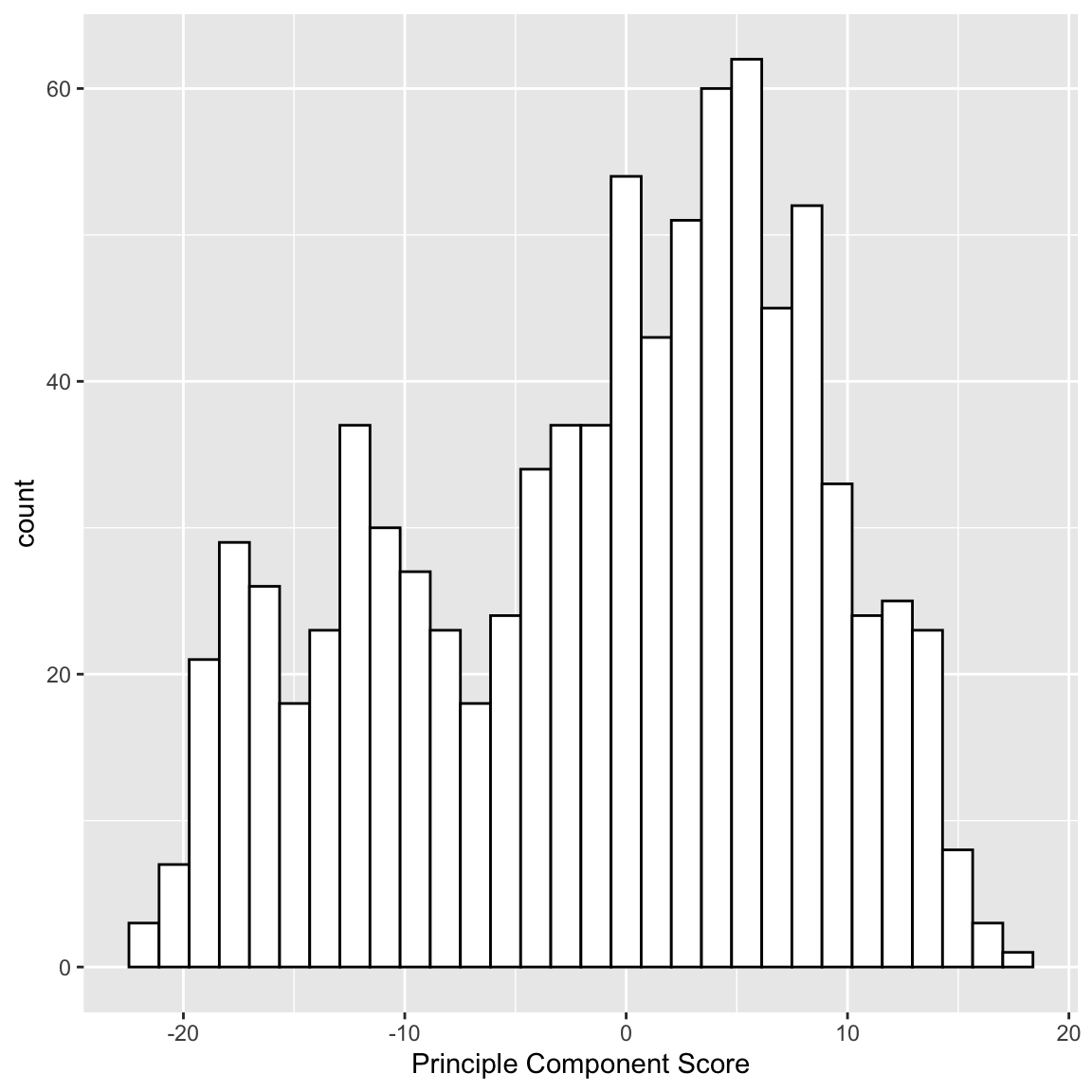
What problem remains? If we are taking the mean, we are treating our two variables \(x^{(1)}\) and \(x^{(2)}\) equally, so that we have a new variable \(z\) that is given by \[z_i=\frac{1}{2}x_i^{(1)}+ \frac{1}{2}x_i^{(2)}\] The idea with principal components, then, is that we want to weight them differently to take into account the scale and whether they are negatively or positively correlated. \[z_i=a_1x_i^{(1)}+ a_2x_i^{(2)}\] So the idea of principal components is to find the “best” constants (or coefficients), \(a_1\) and \(a_2\). This is a little bit like regression, only in regression I had a response \(y_i\), and so my best coefficients were the best predictors of \(y_i\). Here I don’t have a response. I only have the variables, and I want to get the best summary of them, so we will need a new definition of "best’’. So how do we pick the best set of coefficients? Similar to regression, we need a criteria for what is the best set of coefficients. Once we choose the criteria, the computer can run an optimization technique to find the coefficients. So what is a reasonable criteria? If I consider the question of exam scores, what is my goal? Well, I would like a final score that separates out the students so that the students that do much better than the other students are further apart, etc. %Score 2 scrunches most of the students up, so the vertical line doesn’t meet that criteria. The criteria in principal components is to find the line so that the new variable values have the most variance – so we can spread out the observations the most. So the criteria we choose is to maximize the sample variance of the resulting \(z\). In other words, for every set of coefficients \(a_1,a_2\), we will get a set of \(n\) new values for my observations, \(z_1,\ldots,z_n\). We can think of this new \(z\) as a new variable. Then for any set of cofficients, I can calculate the sample variance of my resulting \(z\) as \[\hat{var}(z)=\frac{1}{n-1}\sum_{i=1}^n (z_i-\bar{z})^2\] Of course, \(z_i=a_1x_i^{(1)}+a_2 x_i^{(2)}\), this is actually \[\hat{var}(z)=\frac{1}{n-1}\sum_{i=1}^n (a_1x_i^{(1)}+a_2 x_i^{(2)}-\bar{z})^2\] (I haven’t written out \(\bar{z}\) in terms of the coefficients, but you get the idea.) Now that I have this criteria, I can use optimization routines implemented in the computer to find the coefficients that maximize this quantity. Here is a histogram of the PCA variable \(z\) and that of the mean.
Why maximize variance – isn’t that wrong? We often talk about PCA as “preserving” the variance in our data. But in many settings we say we want low variability, so it frequently seems wrong to students to maximize the variance. But this is because frequently we think of variability as the same thing as noise. But variability among samples should only be considered noise among homogeneous samples, i.e. samples there are no interesting reasons for why they should be different. Otherwise we can have variability in our variables due to important differences between our observations, like what job title our employees have in the SF data in Chapter 2. We can see this in our data examples above, where we see different meaningful groups are separated from each other, such as cancer and normal patients. Genes that have a lot of differences between cancer and normal will have a large amount of spread. The difference in the groups is creating a large spread in our observations. Capturing the variance in PCA is capturing these meaningful differences, as we can see in our above examples. 5.4.1.1 More than 2 variables This procedure expands easily to more than 2 variables. Specifically assume that our observation \(i\) is a vector of values, \((x_i^{(1)},\ldots,x_i^{(p)})\) where \(p\) is the number of variables. With PCA, I am looking for a linear combination of these \(p\) variables. As before, this means we want to multiply each variable by a coefficient and add them together (or subtract if the coefficient is negative) to get a new variable \(z\) for each observation, \[z_i=a_1x_i^{(1)}+\ldots+a_p x_i^{(p)}\] So finding a linear combination is equivalent to finding a set of the \(p\) constants that I will multiply my variables by.
If I take the mean of my \(p\) variables, what are my choices of \(a_k\) for each of my variables? I can similarly find the coefficients \(a_k\) so that my resulting \(z_i\) have maximum variance. PCA is really most powerful when considering many variables.
Unique only up to a sign change Notice that if I multiplied all of the coefficients \(a_k\) by \(-1\), then \(z_i\) will become \(-z_i\). However, the variance of \(-z_i\) will be the same as the variance of \(z_i\), so either answer is equivalent. In general, PCA will only give a unique score \(z_i\) up to a sign change.
You do NOT get the same answer if you multiply only some \(a_k\) by \(-1\), why?
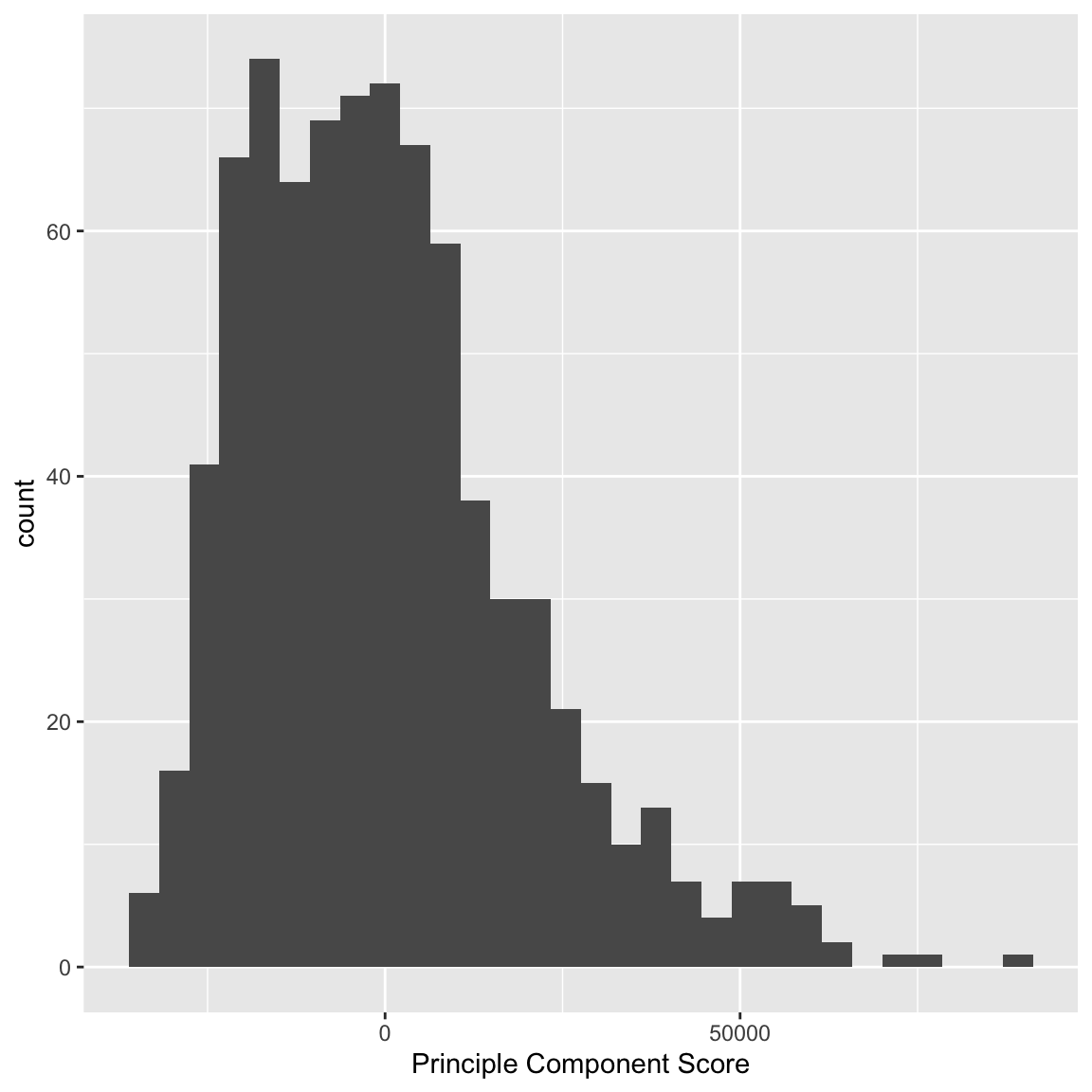
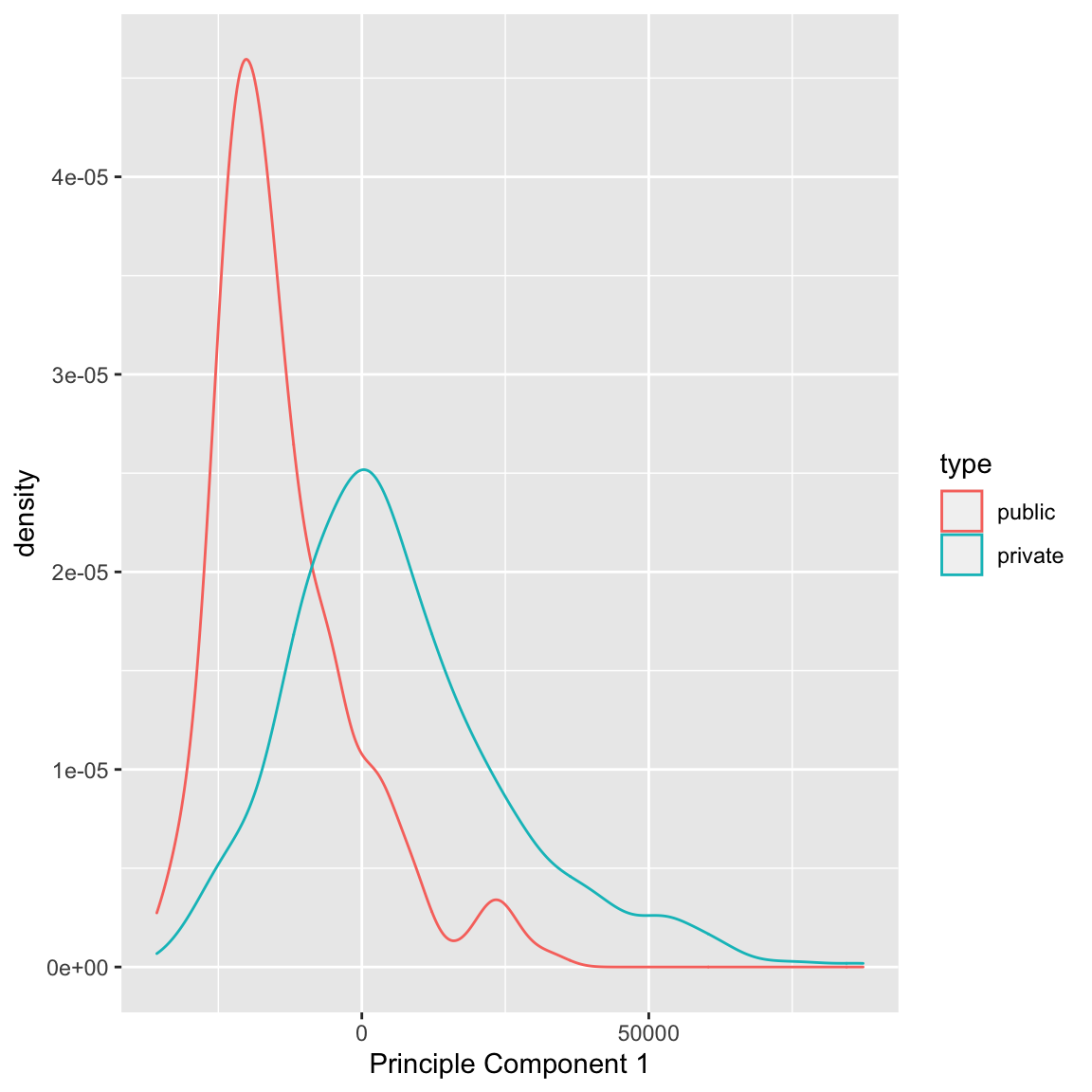
Example: Scorecard Data Consider, for example, our scorecard of colleges data, where we previously only considered the pairwise scatterplots. There are 30 variables collected on each institution – too many to easily visualize. We will consider a PCA summary of all of this data that will incorporate all of these variables. Notice that PCA only makes sense for continuous variables, so we will remove variables (like the private/public split) that are not continuous. PCA also doesn’t handle NA values, so I have removed samples that have NA values in any of the observations. I can plot a histogram of the scores that each observation received:
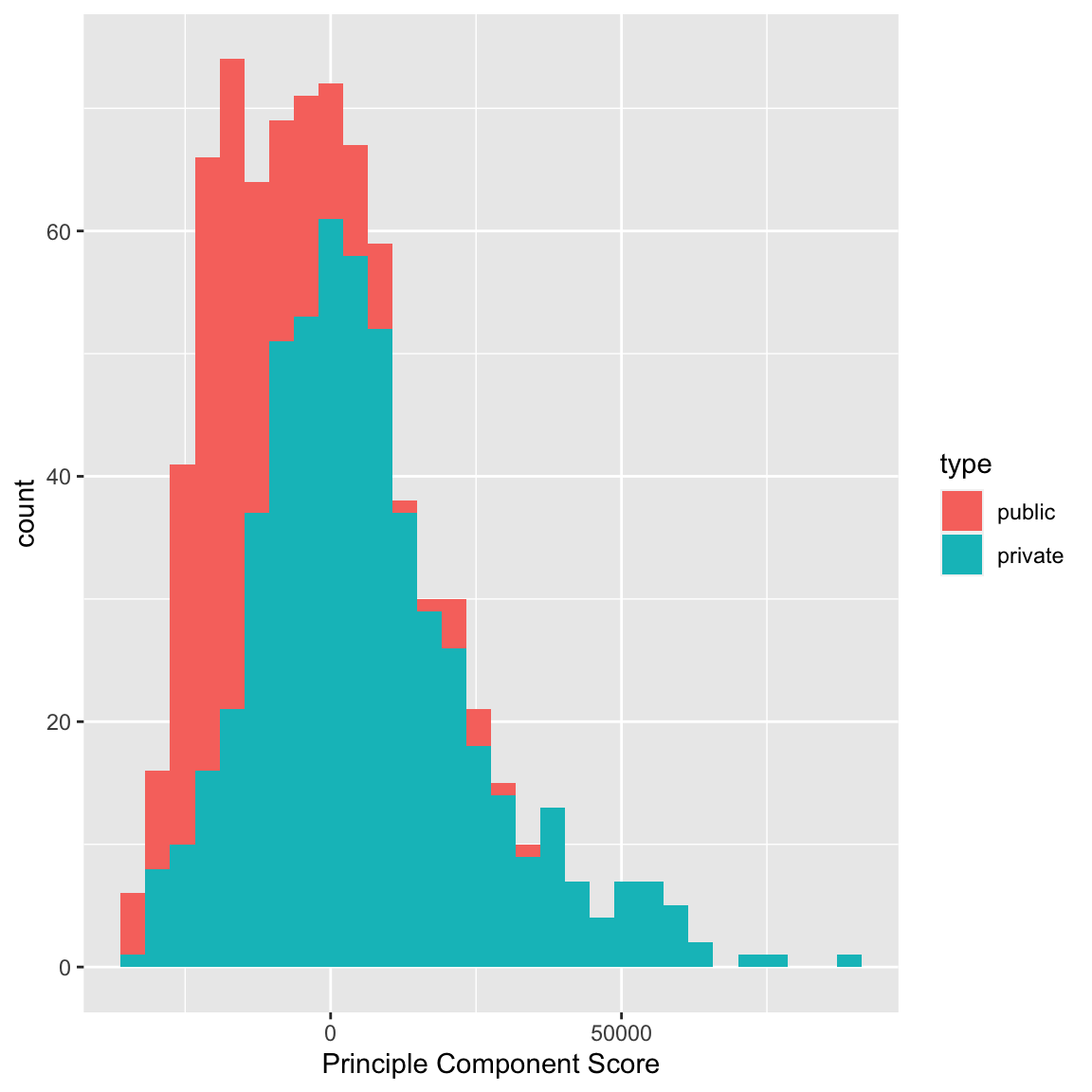
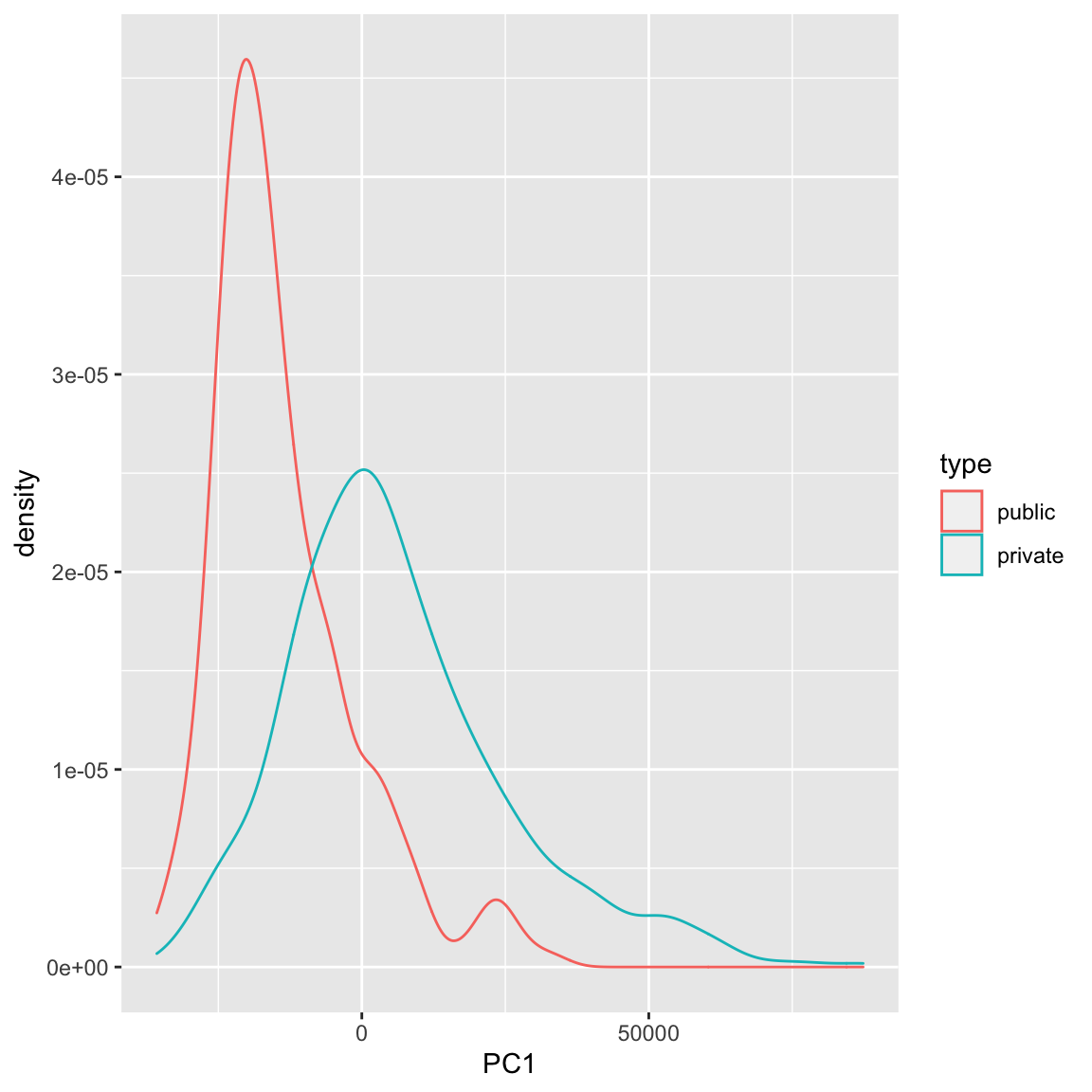
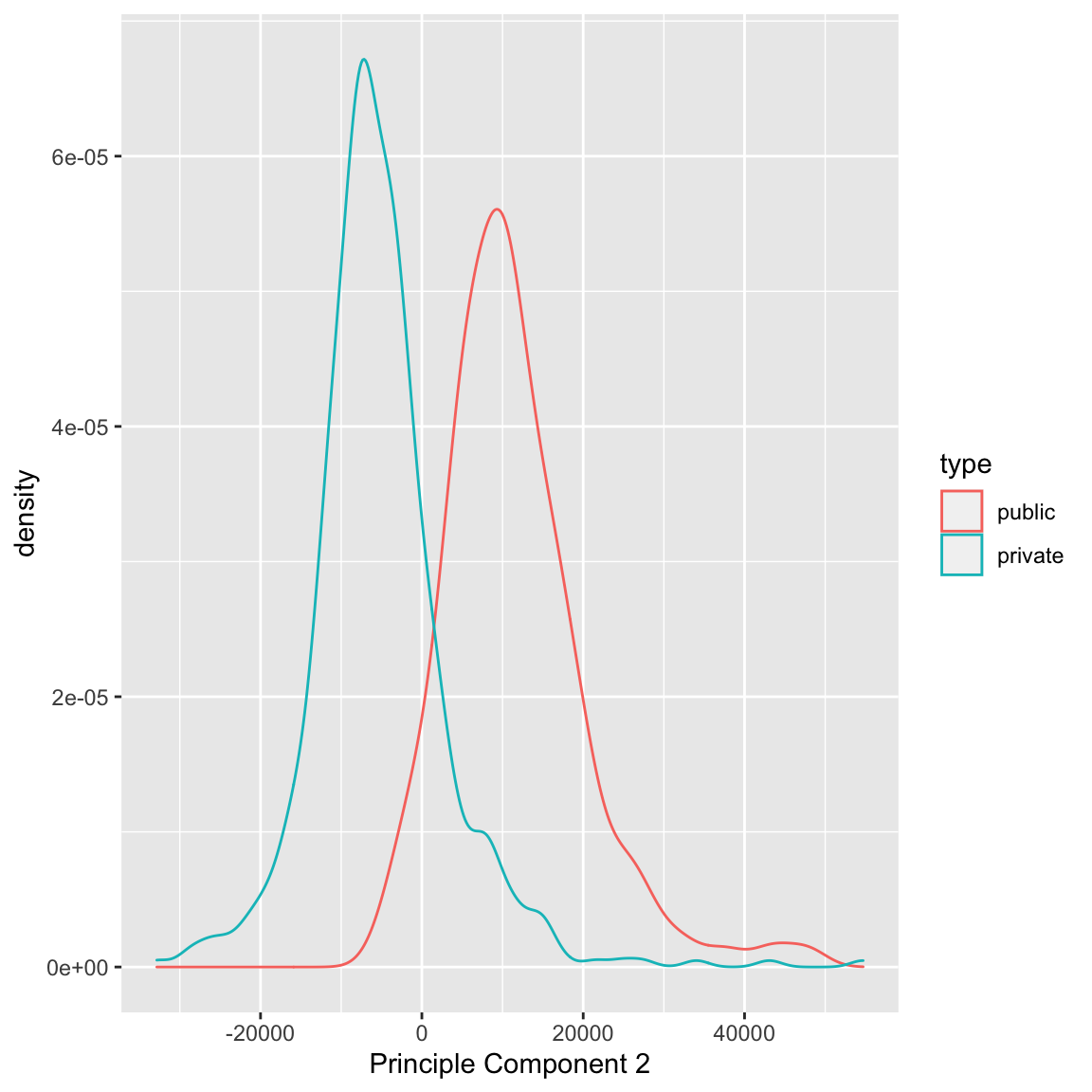
We can see that some observations have quite outlying scores. When I manually look at their original data, I see that these scores have very large (or very small) values for most of the variables, so it makes sense that they have outlying scores. I can also compare whether public and private colleges seem to be given different scores:
We can see some division between the two, with public seeming to have lower scores than the private. Notice that I only care about relative values here – if I multiplied all of my coefficients \(a_k\) by \(-1\), then I would flip which is lower or higher, but it would be equivalent in terms of the variance of my new scores \(z_i\). So it does not mean that public schools are more likely to have lower values on any particular variables; it does mean that public schools tend to have values that are in a different direction than private schools on some variables.
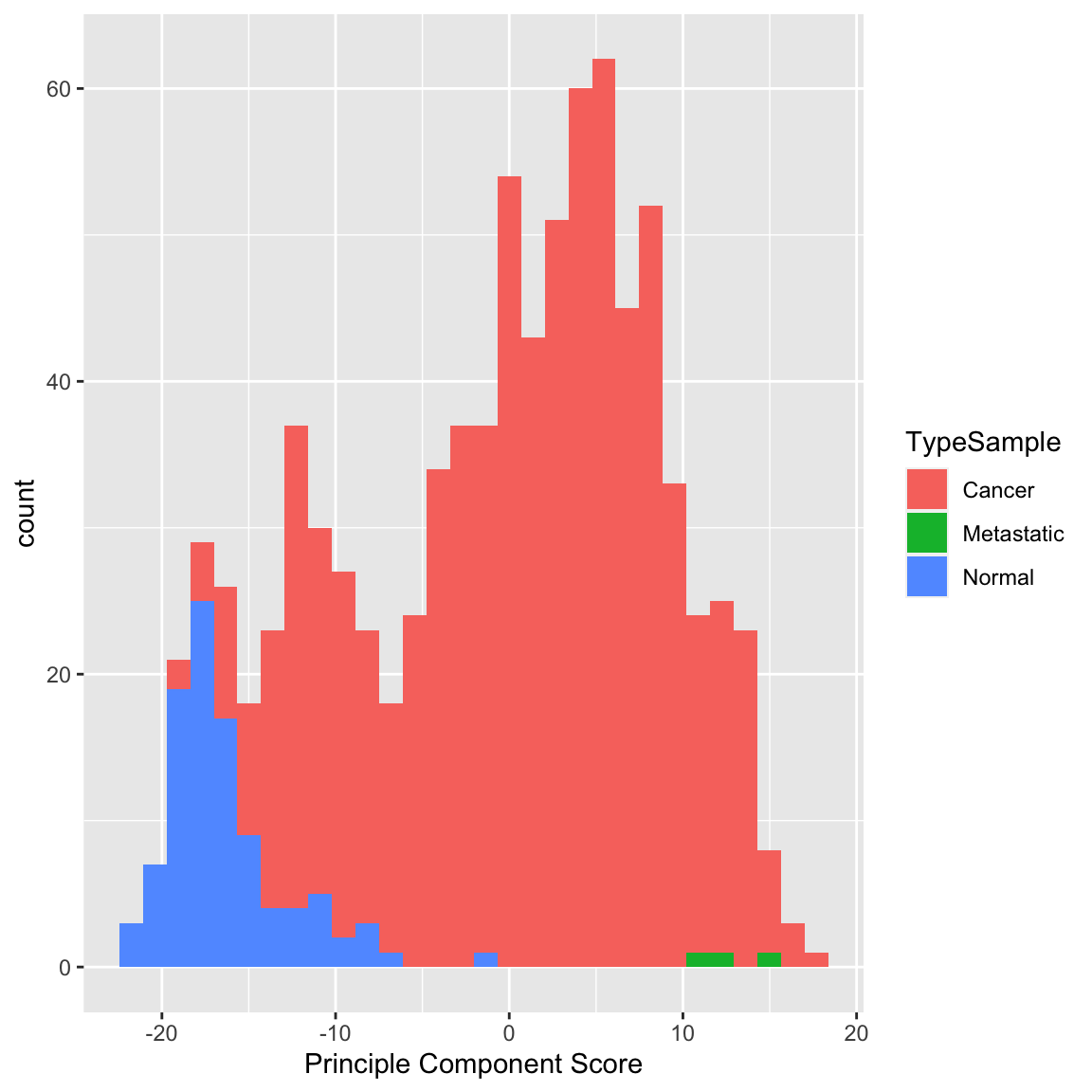
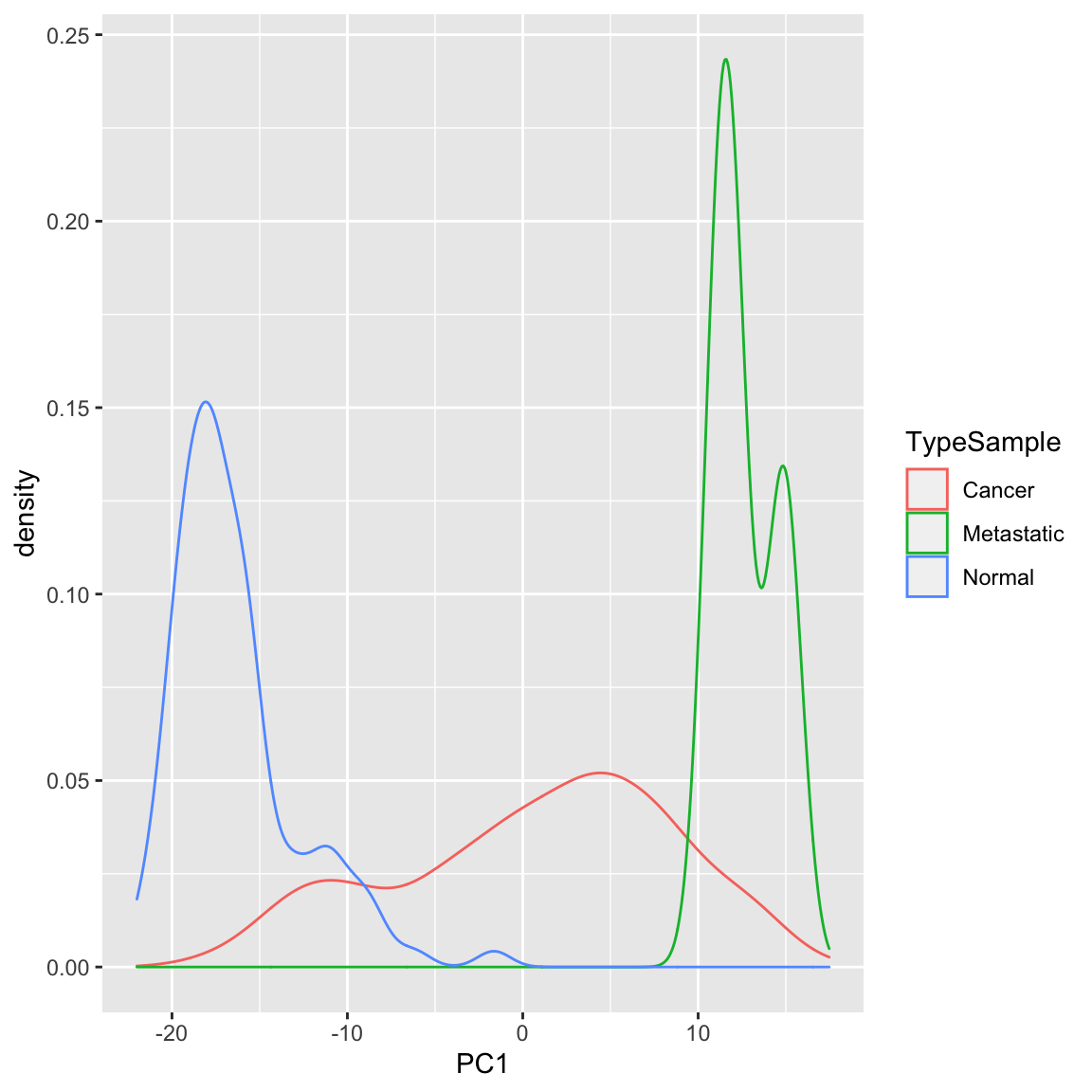
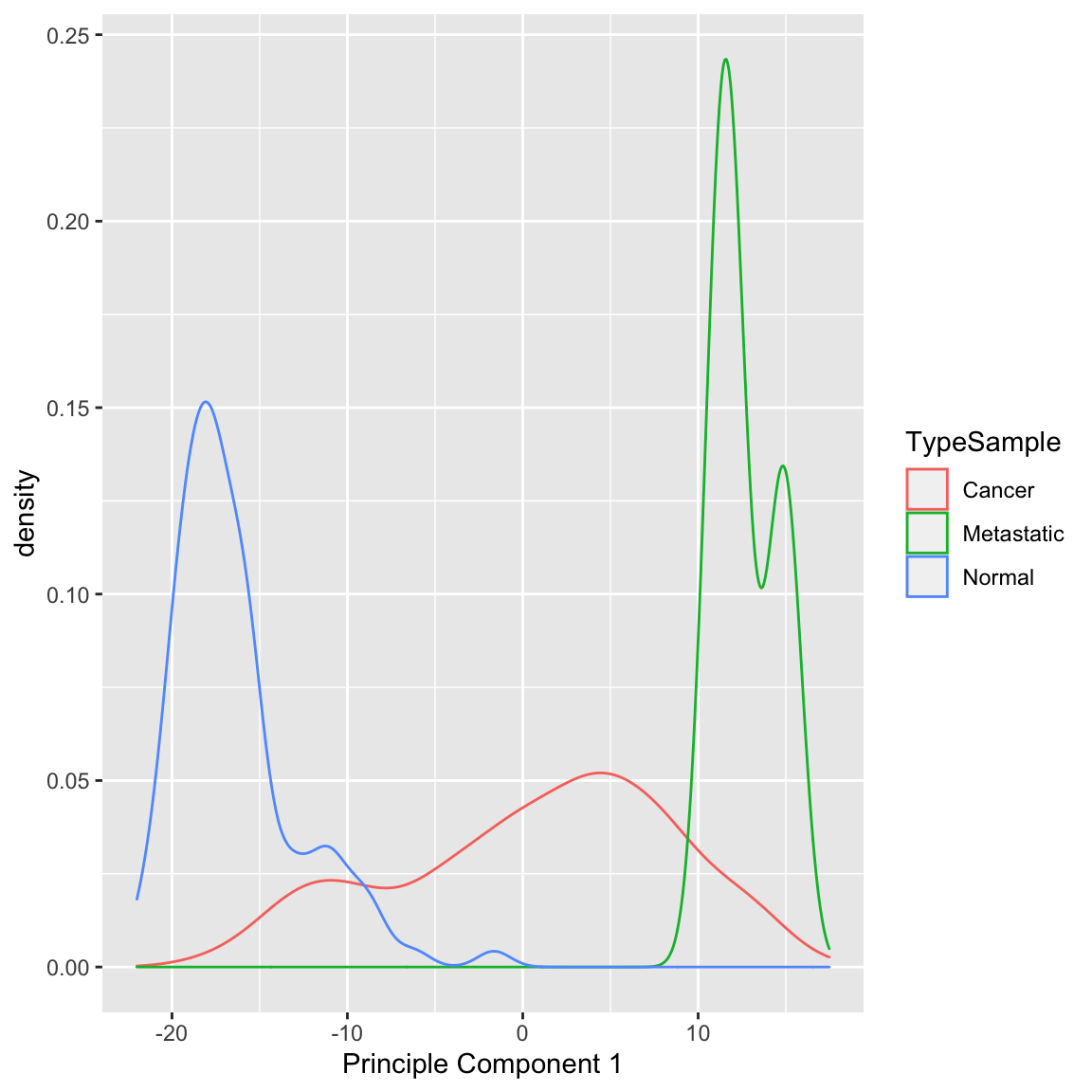
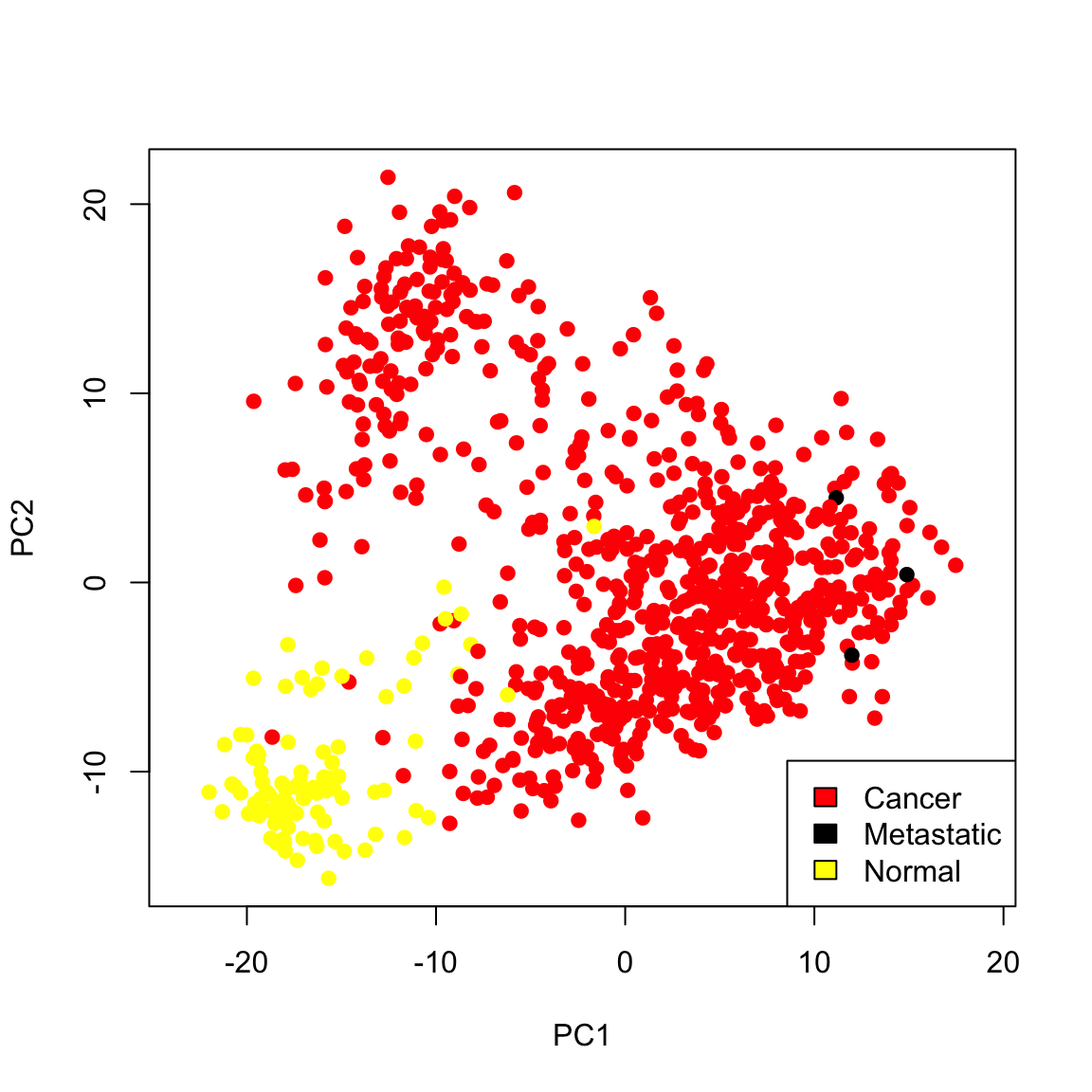
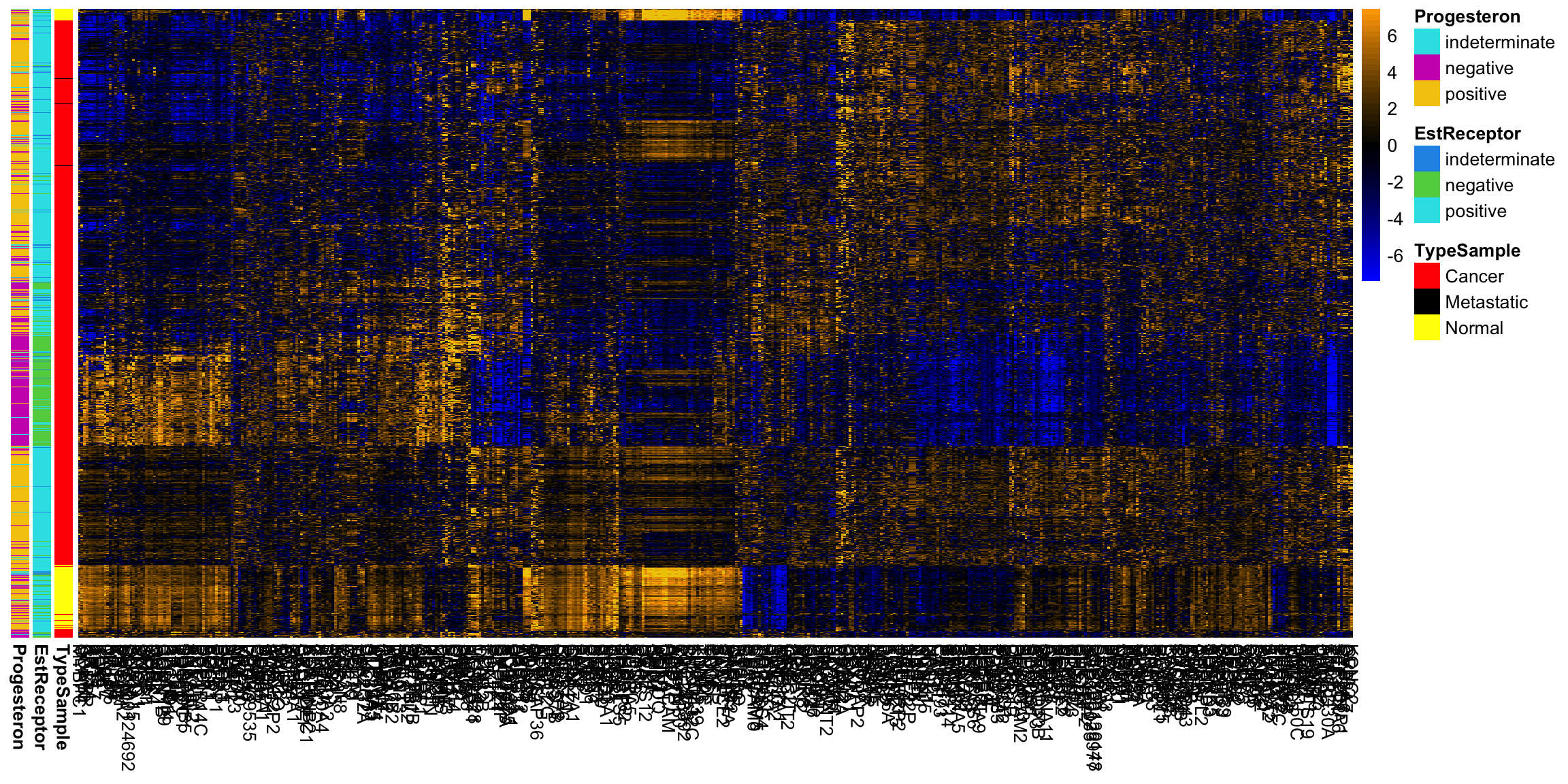
Example: Breast Cancer Data Similarly we can see a big difference between cancer and normal observations in the first two principal components.
We can see that, at least based on the PC score, there might be multiple groups in this data, because there are multiple modes. We could explore the scores of normal versus cancer samples, for example:
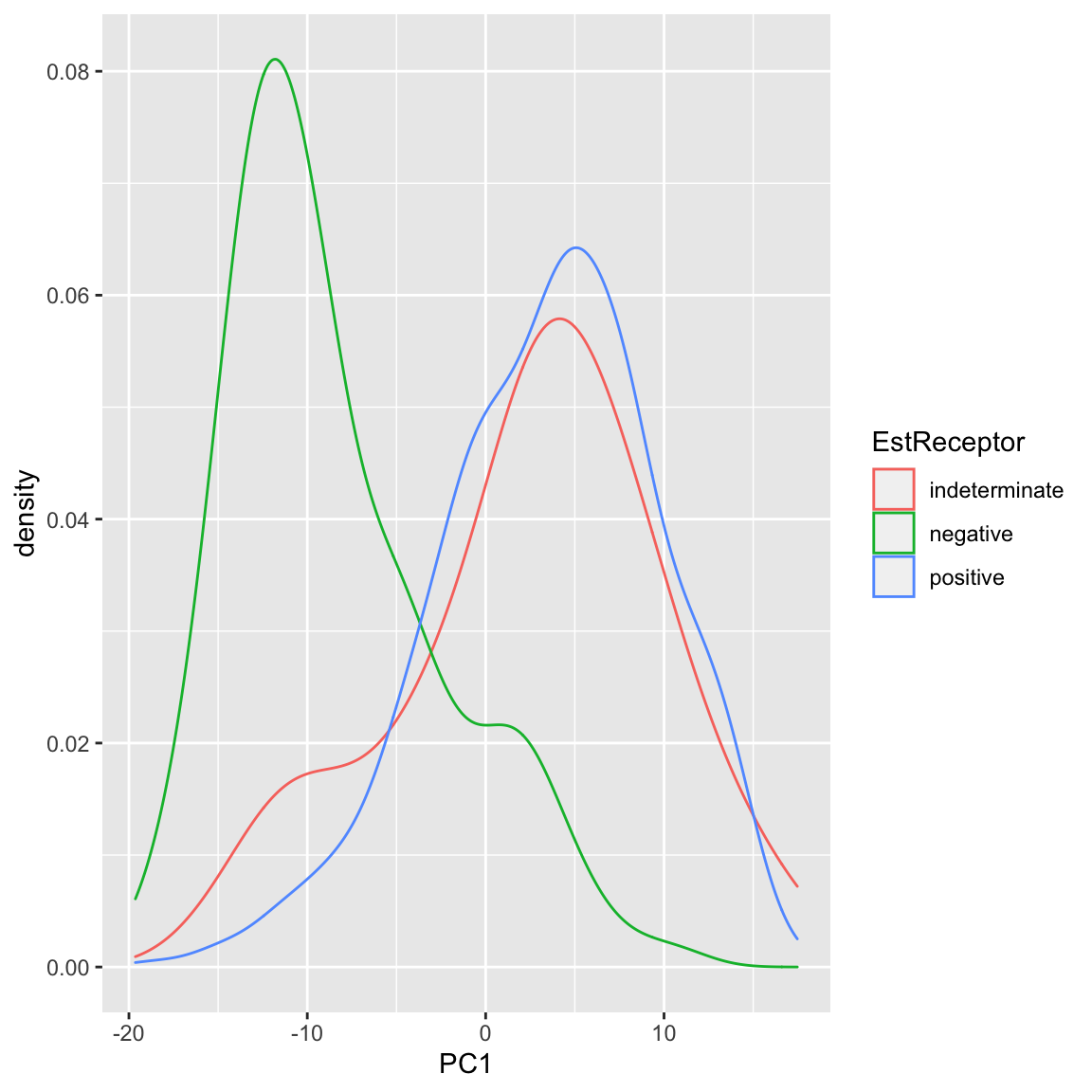
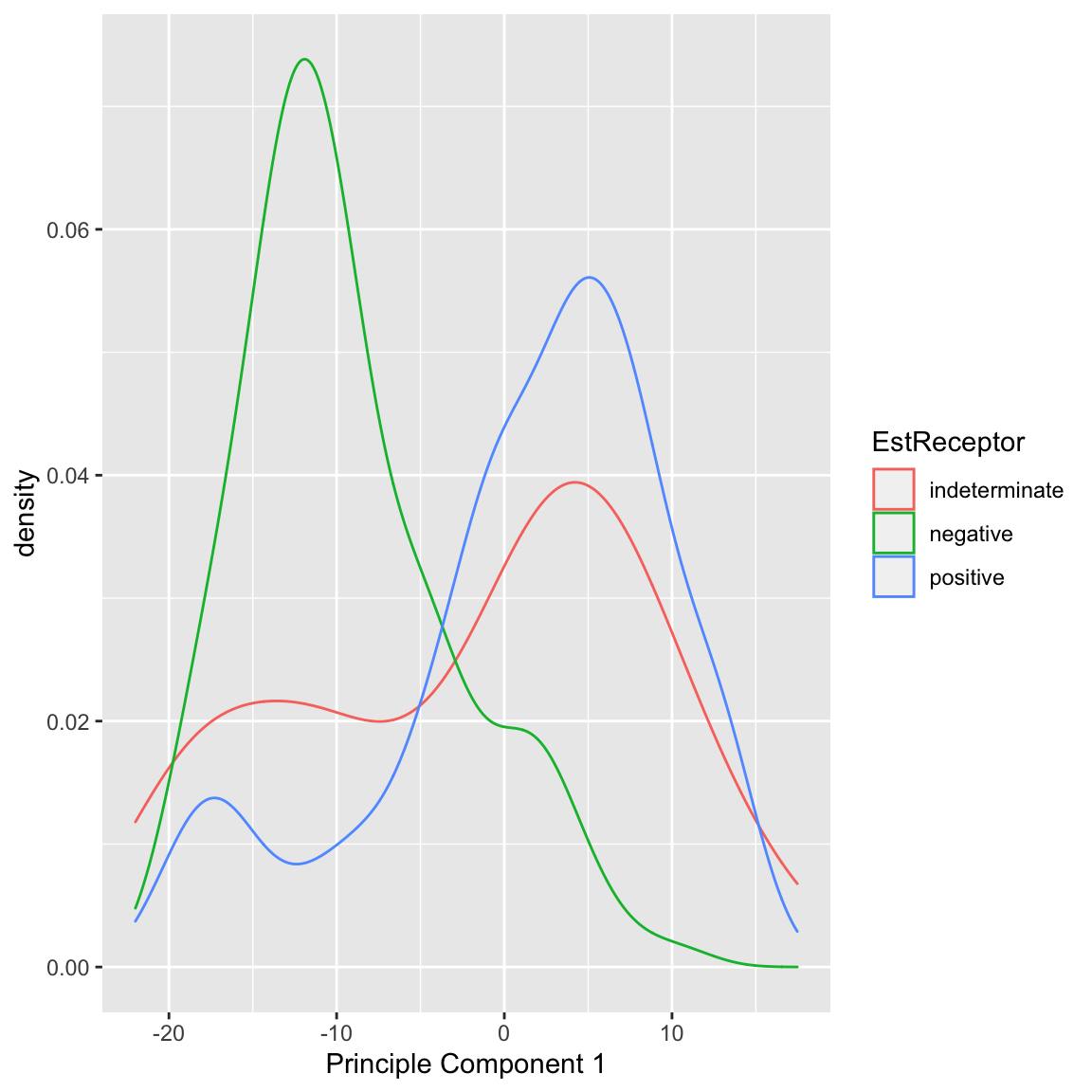
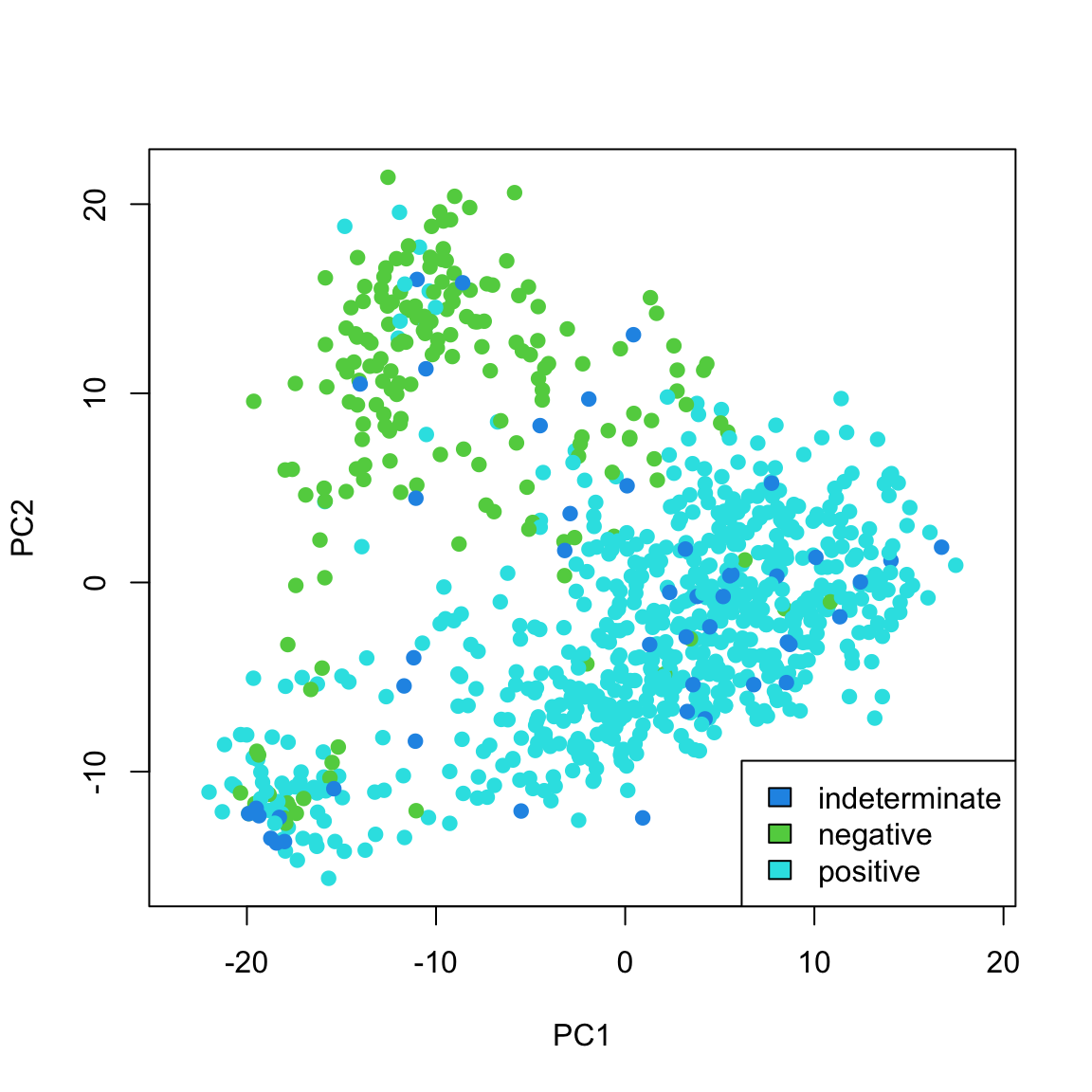
We can also see that cancer samples are really spread out; we have other variables that are particularly relevant for separating cancer samples, so we could see how they differ. For example, by separating estrogen receptor status, we see quite different distributions:
In summary, based on our PCA score, I can visually explore important patterns in my data, even with very large numbers of variables. Because I know that this is the linear combination that most spreads out my observations, hopefully large shared differences between our samples (like normal vs cancer, or outlying observations) will be detected, particularly if they are reiterated in many variables. 5.4.1.2 Multiple principal components So far we have found a single score to summarize our data. But we might consider that a single score is not going to capture the complexity in the data. For example, for the breast cancer data, we know that the normal and cancer samples are quite distinct. But we also know that within the cancer patients, those negative on the Estrogen Receptor or Progesteron are themselves a subgroup within cancer patients, in terms of their gene measurements. Capturing these distinctions with a single score might be to difficult. Specifically, for each observation \(i\), we have previously calculated a single score, \[\begin{align*} z=a_1x^{(1)}+\ldots+a_px^{(p)}\\ \end{align*}\] What if instead we want two scores for each observation \(i\), i.e. \((z_i^{(1)},z_i^{(2)})\). Again, we want each score to be linear combinations of our original \(p\) variables. This gives us \[\begin{align*} z^{(1)}=a_1^{(1)}x^{(1)}+\ldots+a_p^{(1)}x^{(p)}\\ z^{(2)}=b_1^{(2)}x^{(1)}+\ldots+b_p^{(2)}x^{(p)} \end{align*}\] Notice that the coefficients \(a_1^{(1)},\ldots,a_p^{(1)}\) belong to our first PC score, \(z^{(1)}\), and the second set of coefficients \(b_1^{(2)},\ldots,b_p^{(2)}\) are entirely different numbers and belong to our second PC score, \(z^{(2)}\). We can think of this as going from each observation having data \((x^{(1)},\ldots,x^{(p)})\) to now having \((z^{(1)},z^{(2)})\) as their summarized data. This is often called a reduced dimensionality representation of our data, because we are going from \(p\) variables to a reduced number of summary variables (in this case 2 variables). More generally, if we have many variables, we can use the principal components to go from many variables to a smaller number. How are we going to choose \((z^{(1)},z^{(2)})\)? Previously we chose the coefficients \(a_k\) so that the result is that \(z^{(1)}\) has maximal variance. Now that we have two variables, what properties do we want them to have? They clearly cannot both maximimize the variance, since there’s only one way to do that – we’d get \(z^{(1)}=z^{(2)}\) which doesn’t give us any more information about our data! So we need to say something about how the new variables \(z^{(1)},z^{(2)}\) relate to each other so that jointly they maximally preserve information about our original data. How can we quantify this idea? There are ways of measuring the total variance between multiple variables \(z^{(1)}\) and \(z^{(2)}\) variables, which we won’t go into in detail. But we’ve seen that when variables are highly correlated with each other, they don’t give a lot more information about our observations since we can predict one from the other with high confidence (and if perfectly correlated we get back to \(z^{(1)}=z^{(2)}\)). So this indicates that we would want to choose our coefficients \(a_1^{(1)},\ldots,a_p^{(1)}\) and \(b_1^{(2)},\ldots,b_p^{(2)}\) so that the resulting \(z^{(1)}\) and \(z^{(2)}\) are completely uncorrelated. How PCA does this is the following: Choose \(a_1^{(1)}\ldots a_p^{(1)}\) so that the resulting \(z_i^{(1)}\) has maximal variance. This means it will be exactly the same as our PC that we found previously. Choose \(b_1^{(2)},\ldots,b_p^{(2)}\) so that the resulting \(z_i^{(2)}\) is uncorrelated with the \(z_i^{(1)}\) we have already found. That does not create a unique score \(z_i^{(2)}\) (there will be many that satisfy this property). So we have the further requirement Among all \(b_1^{(2)},\ldots,b_p^{(2)}\) that result in \(z_i^{(2)}\) uncorrelated with \(z_i^{(1)}\), we choose \(b_1^{(2)},\ldots,b_p^{(2)}\) so that the resulting \(z_i^{(2)}\) have maximal variance. This sounds like a hard problem to find \(b_1^{(2)},\ldots,b_p^{(2)}\) that satisfies both of these properties, but it is actually equivalent to a straightforward problem in linear algebra (related to SVD or eigen decompositions of matrices). The end result is that we wind up with two new variables for each observation and these new variables have correlation equal to zero and jointly “preserve” the maximal amount of variance in our data.
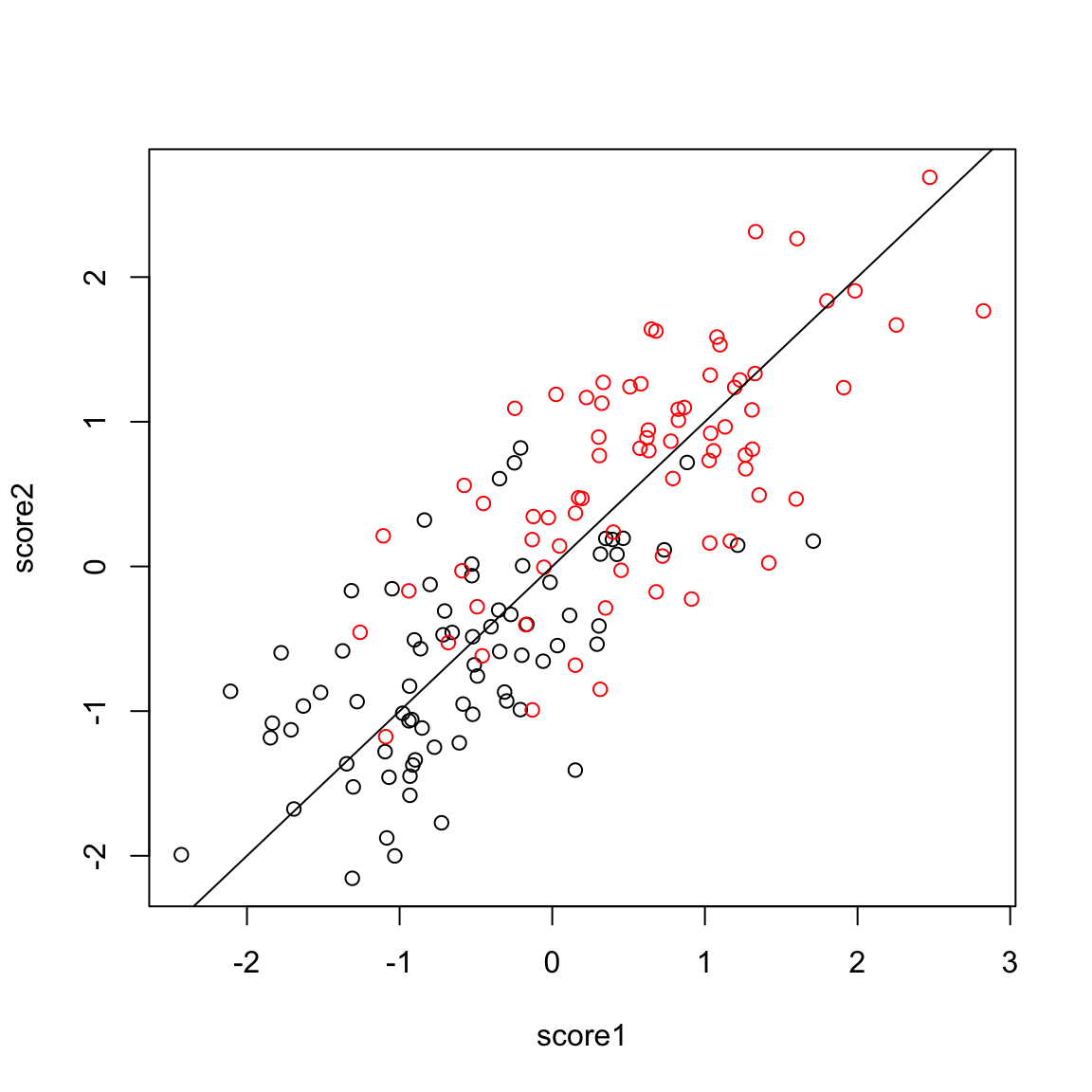
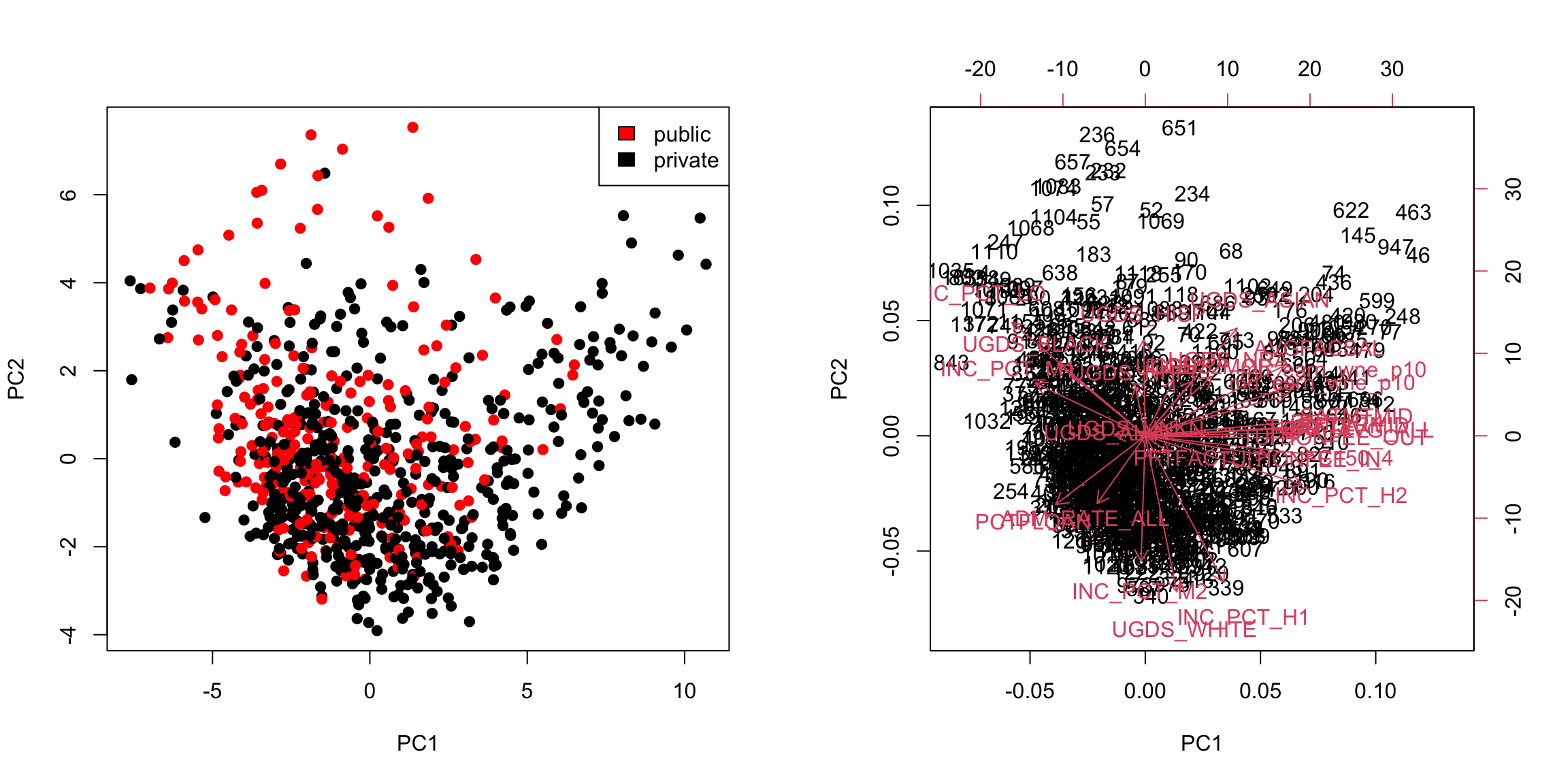
Example: College Data Let’s consider what going to two PC components does for our previous data examples. Previously in the college data, with one principal component we saw that there was a difference in the distribution of scores, but that was also a great deal of overlap. Individually, we can consider each PC, and see that there is a bit more separation in PC2 than PC1
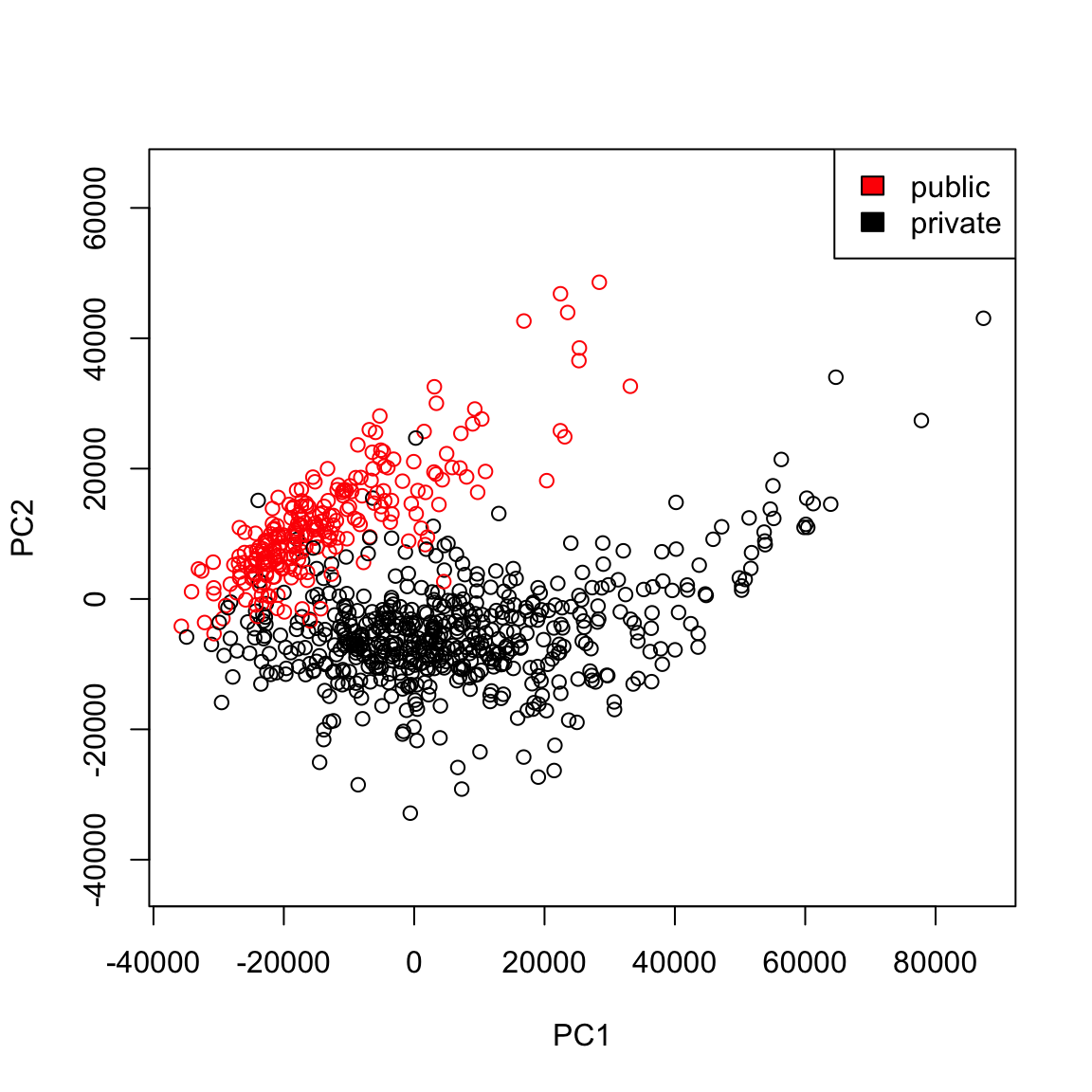
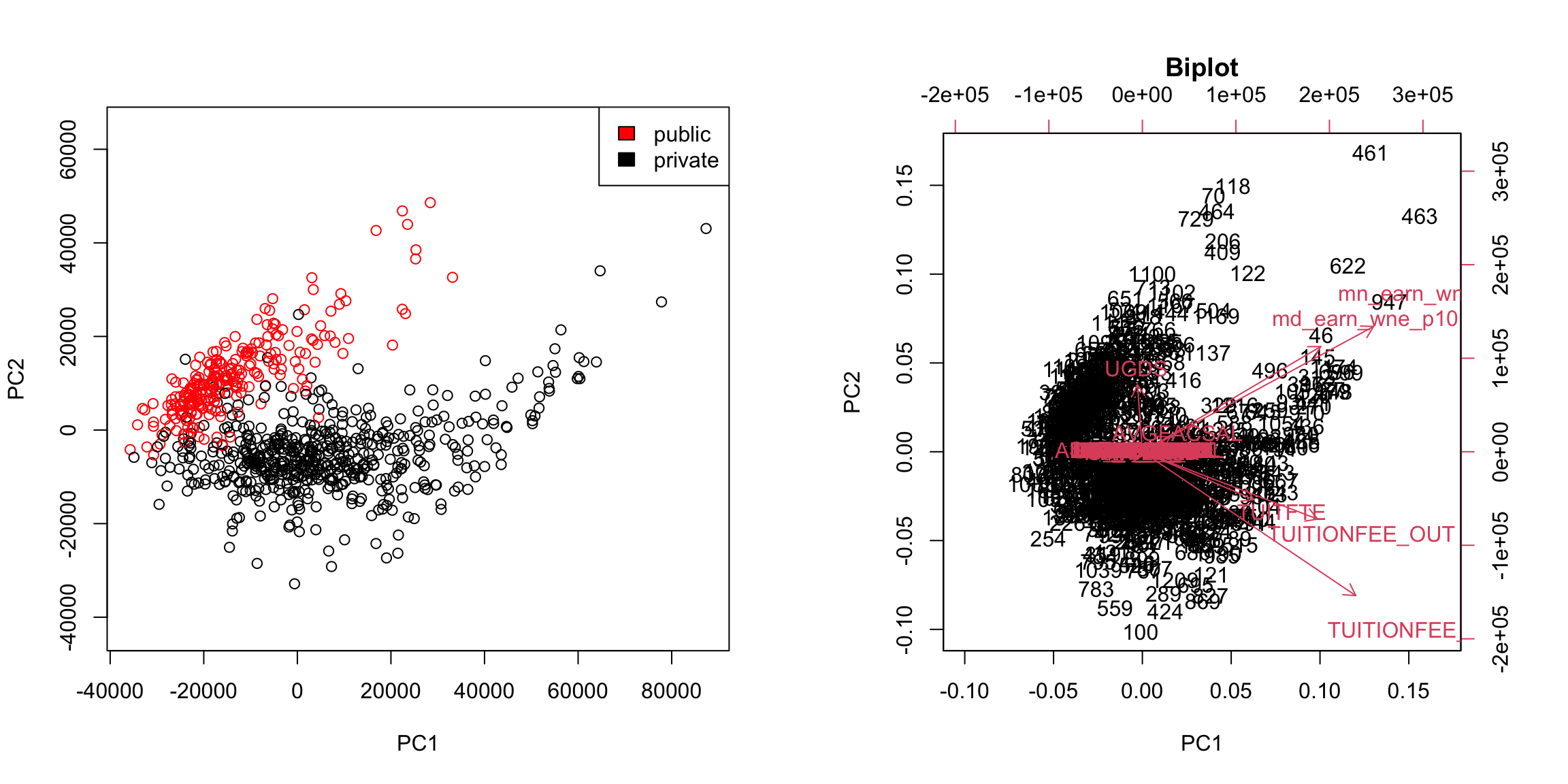
But even more importantly, we can consider these variables jointly in a scatter plot: plot(pcaCollegeDf[, c("PC1", "PC2")], col = c("red", "black")[pcaCollegeDf$type], asp = 1) legend("topright", c("public", "private"), fill = c("red", "black"))
We see that now the public and private are only minimally overlapping; we’ve gained a lot of information about this particular distinction (public/private) by adding in PC2 in addition to PC1. Remember, we didn’t use the public or private variable in our PCA; and there is no guarantee that the first PCs will capture the differences you are interested in. But when these differences create large distinctions in the variables (like the public/private difference does), then PCA is likely to capture this difference, enabling you to use it effectively as a visualization tool.
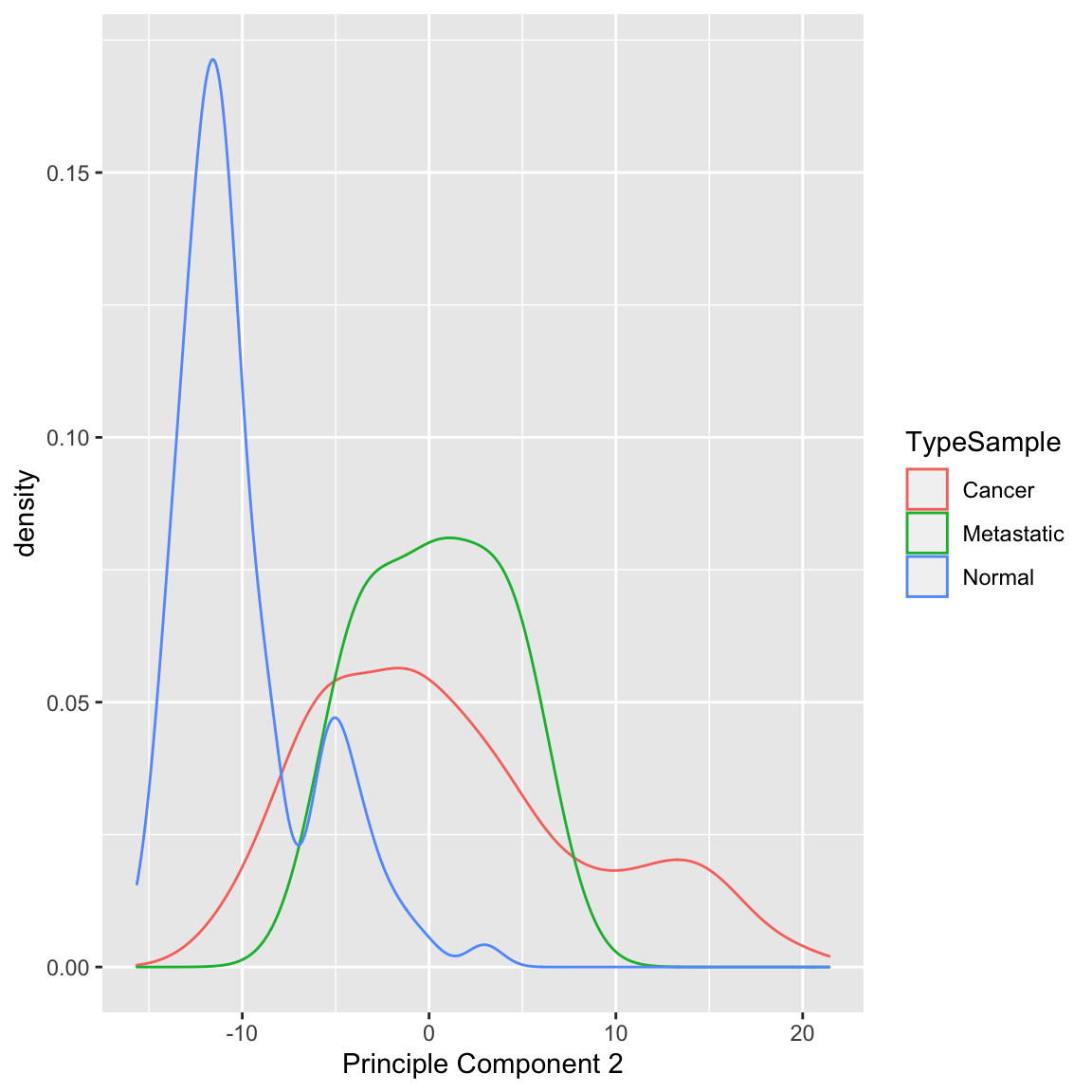
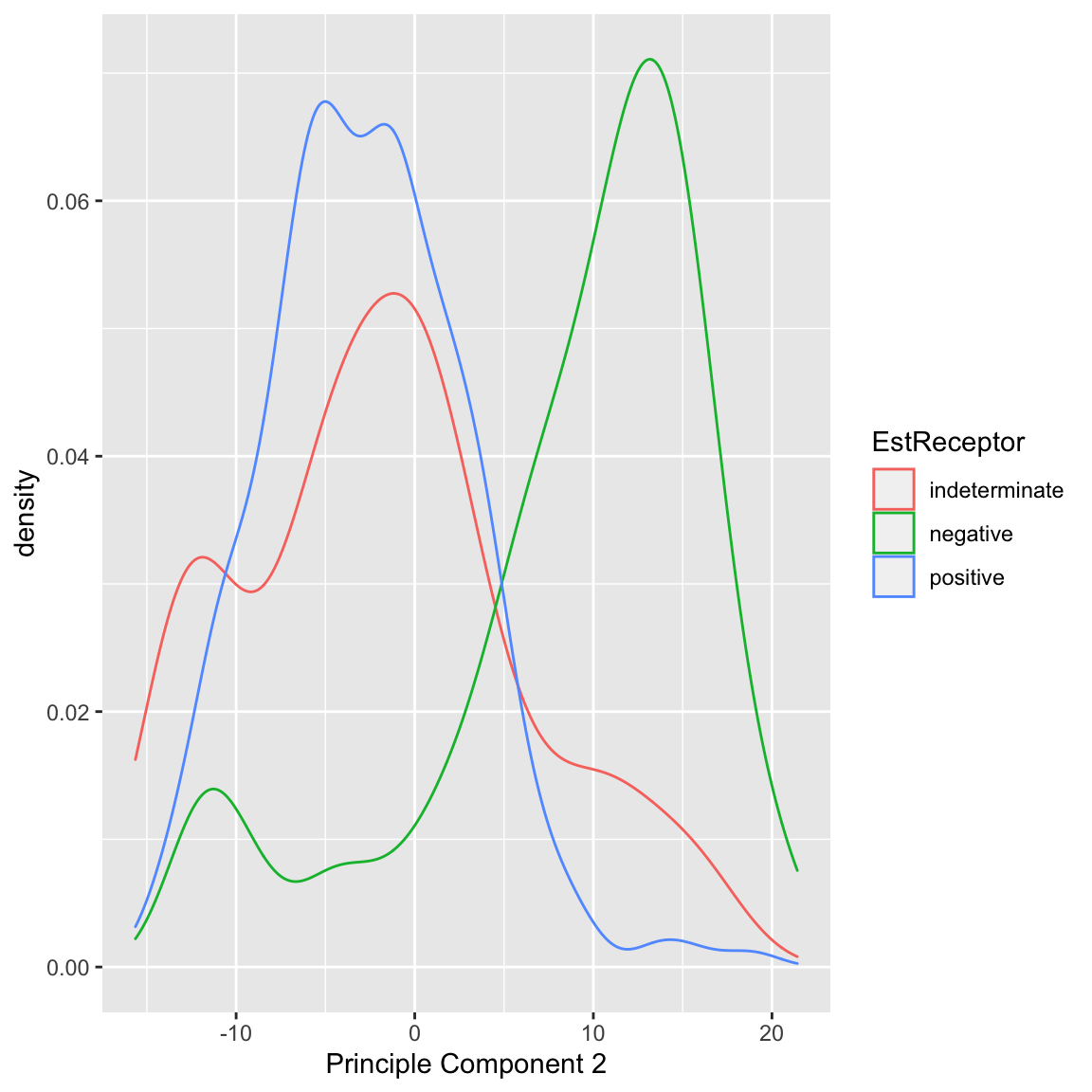
Example: Breast Cancer Data We now turn to the breast cancer data. We can see that PC2 is probably slightly worse at separating normal from cancer compared to PC1 (and particularly doesn’t give similar scores to metastases):
It does a arguably a better job of separating our negative estrogen receptor patients:
When we consider these variables jointly in a scatter plot we see much greater separation:
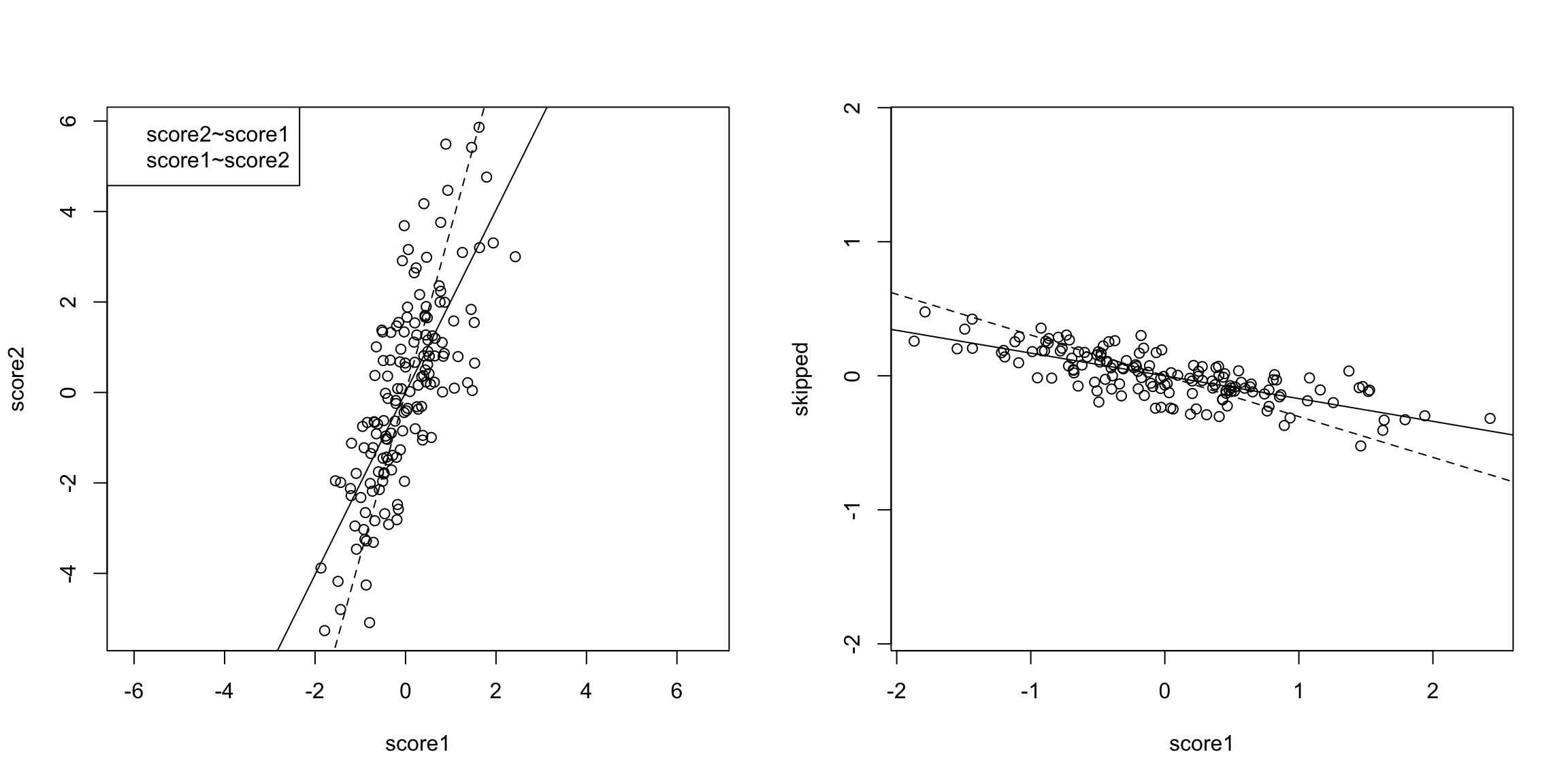
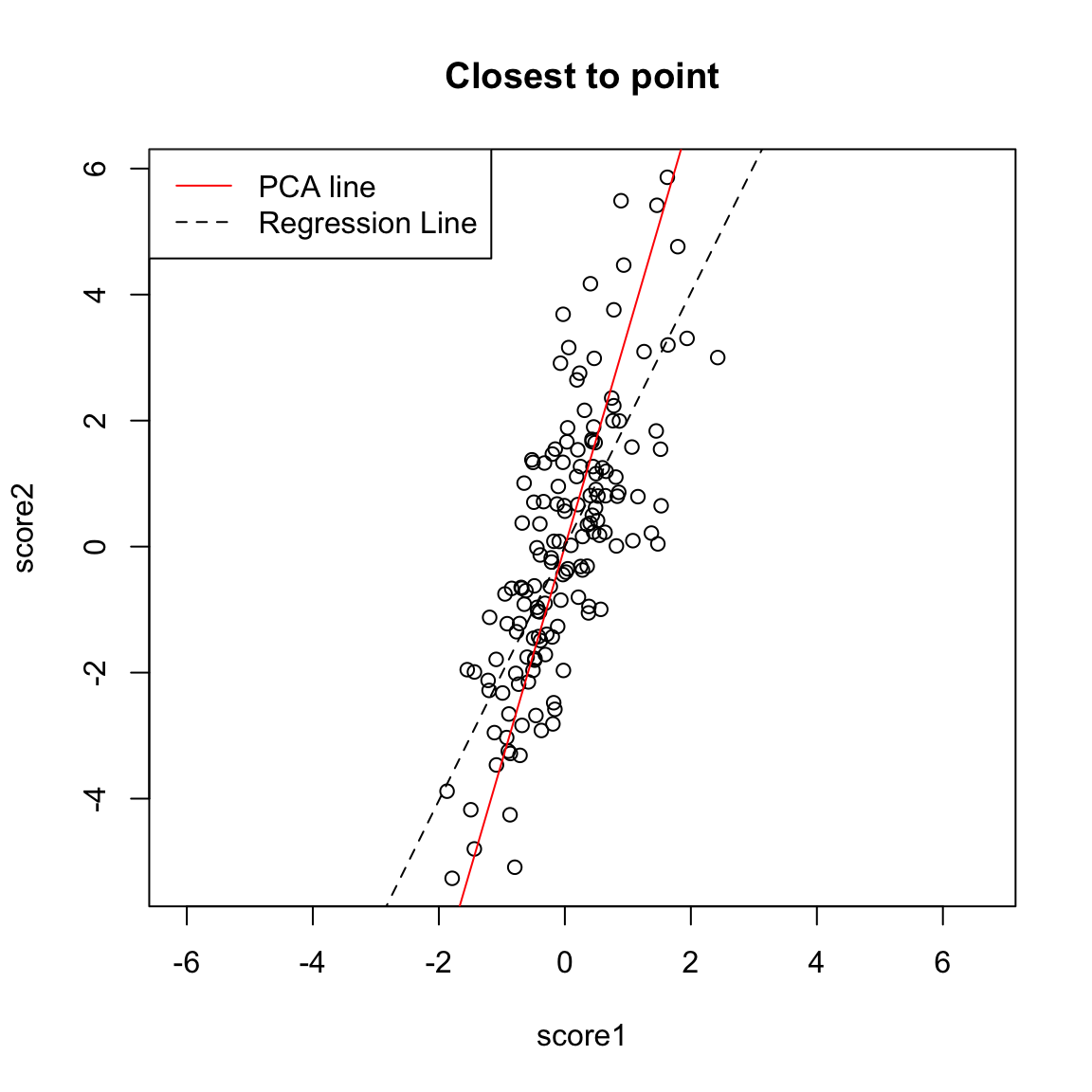
What differences do you see when you use both principal components rather than either one singly? 5.4.2 Geometric Interpretation Another way to consider our redundancy is geometrically. If this was a regression problem we would “summarize” the relationship betweeen our variables by the regression line:
This is a summary of how the x-axis variable predicts the y-axis variable. But note that if we had flipped which was the response and which was the predictor, we would give a different line.
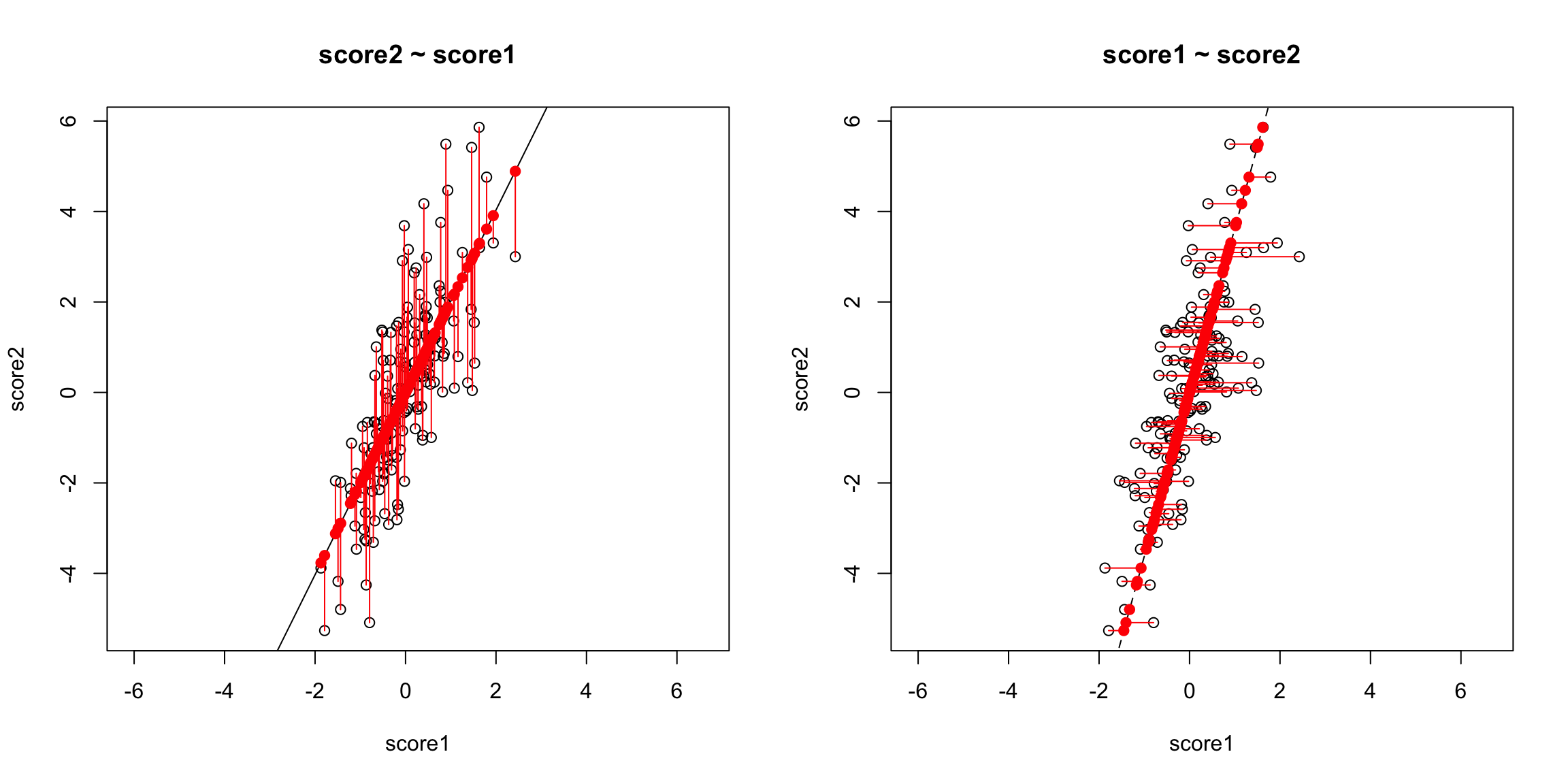
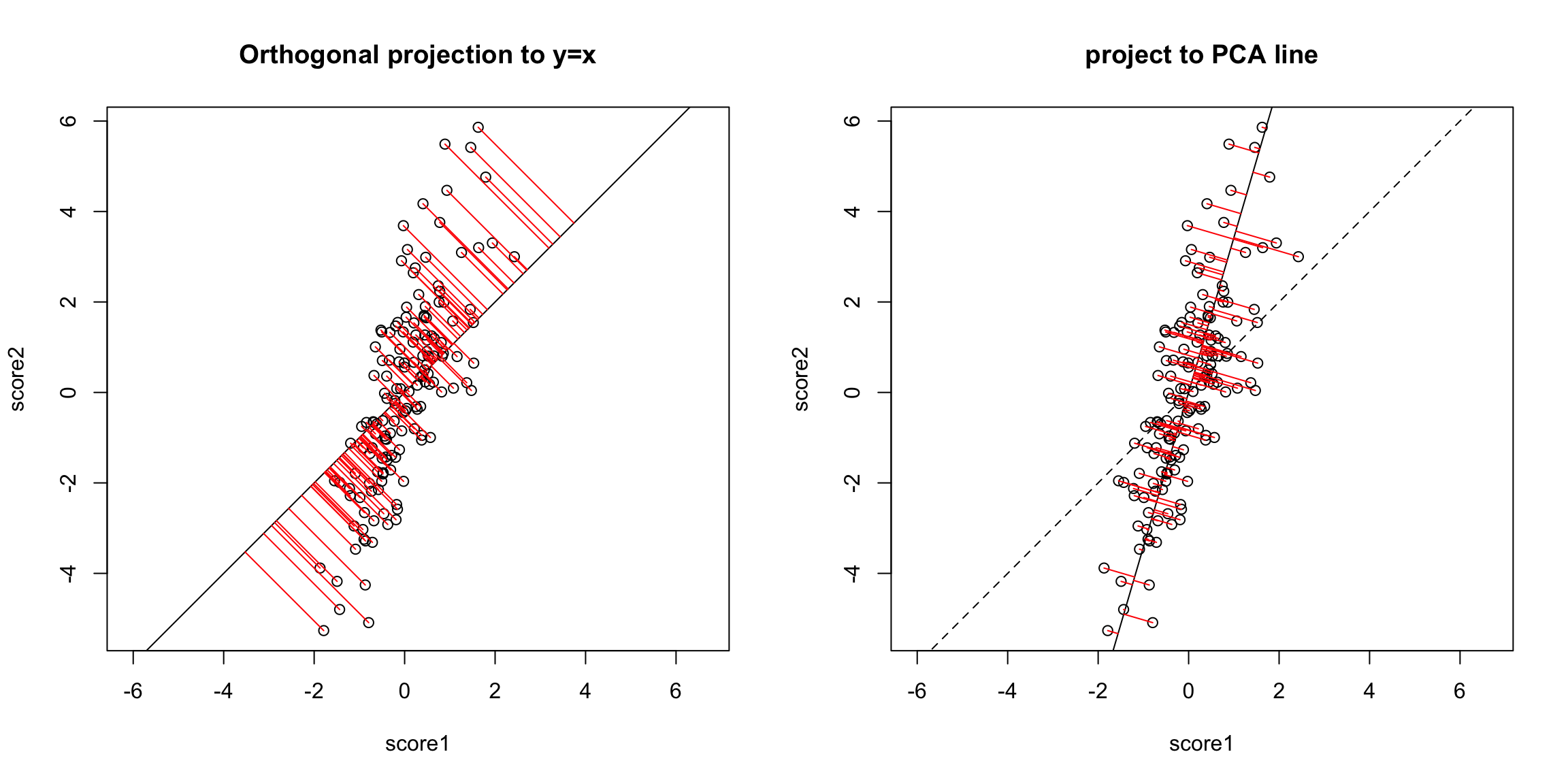
The problem here is that our definition of what is the best line summarizing this relationship is not symmetric in regression. Our best line minimizes error in the y direction. Specifically, for every observation \(i\), we project our data onto the line so that the error in the \(y\) direction is minimized.
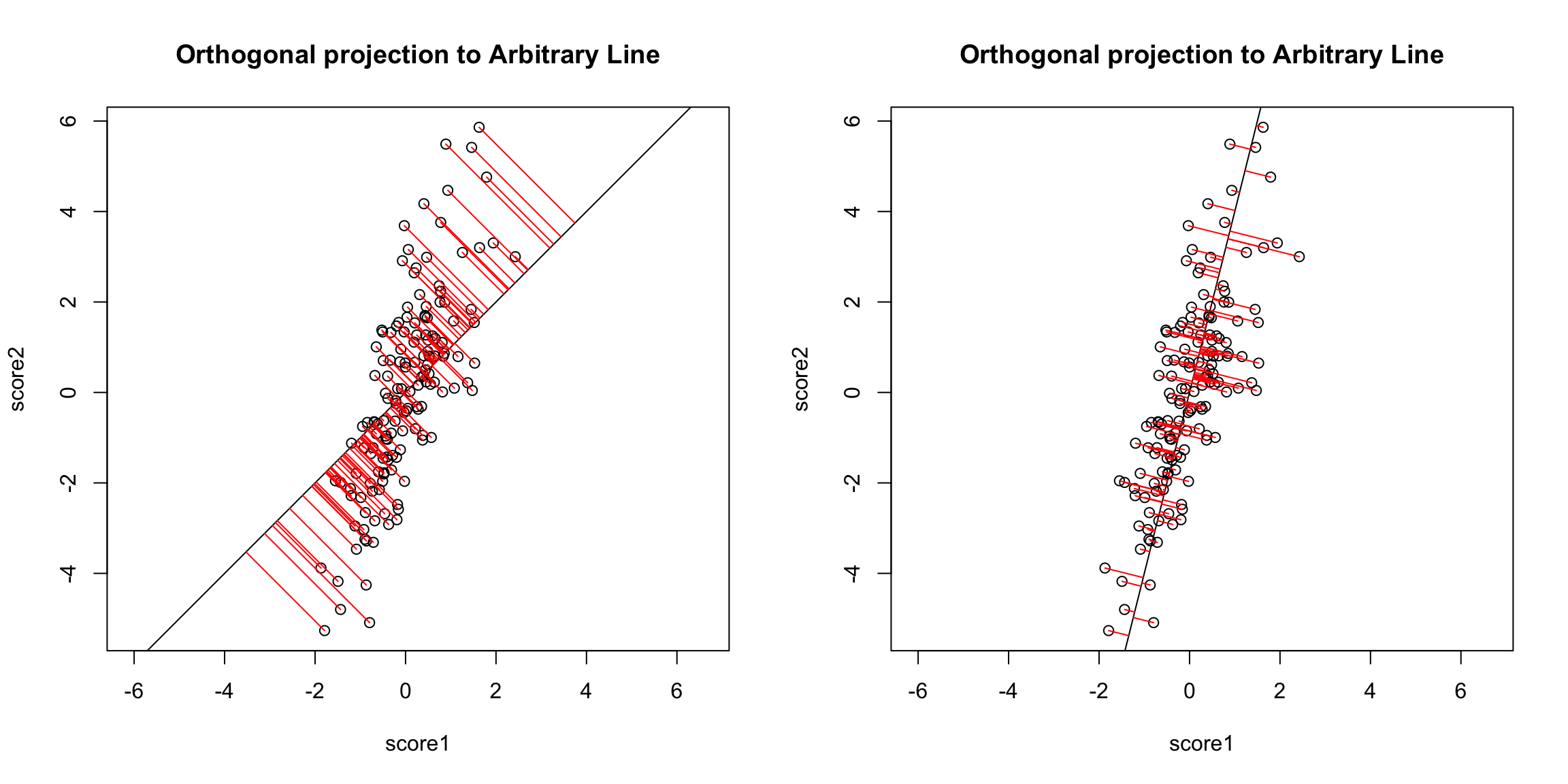
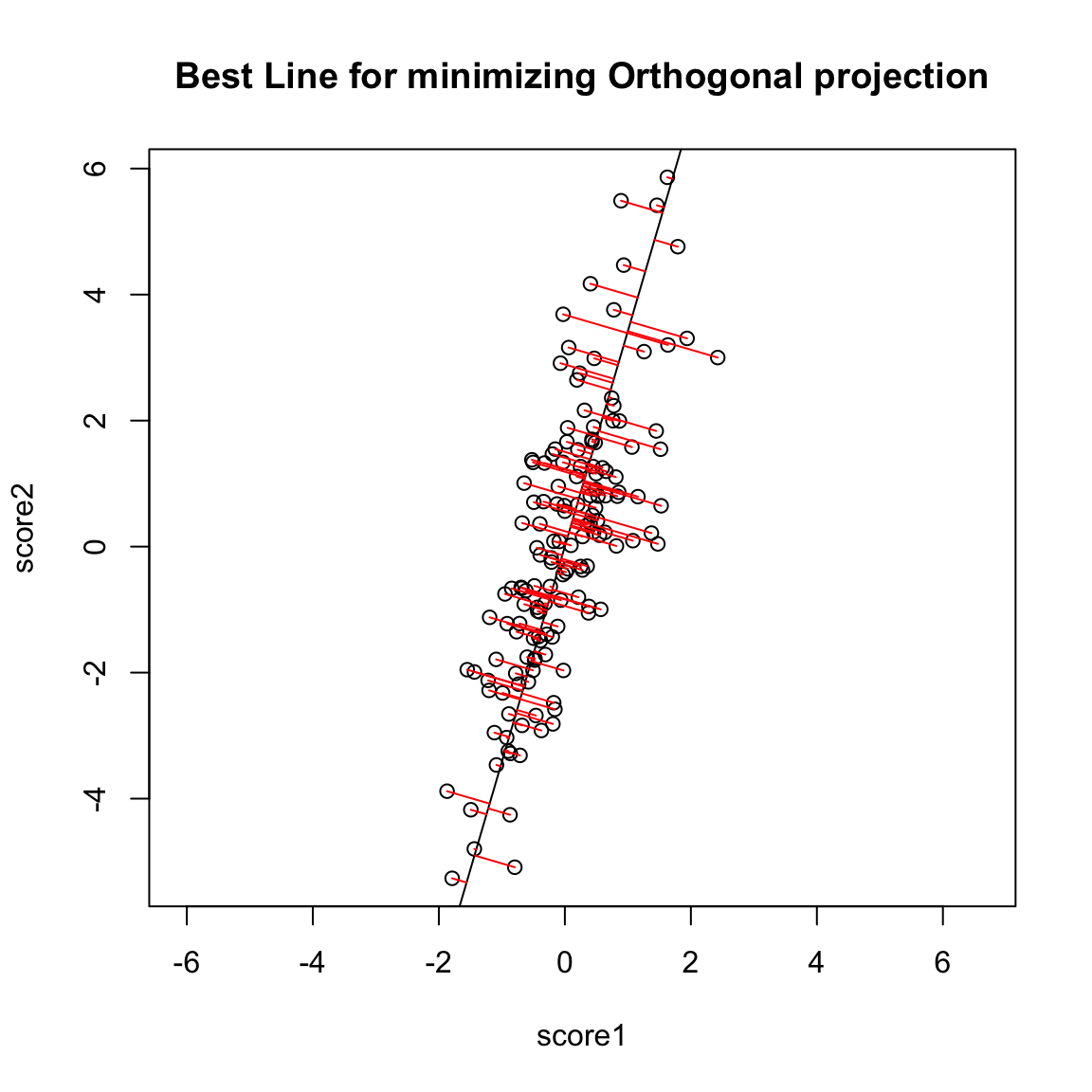
However, if we want to summarize both variables symmetrically, we could instead consider picking a line to minimize the distance from each point to the line. By distance of a point to a line, we mean the minimimum distance of any point to the line. This is found by drawing another line that goes through the point and is orthogonal to the line. Then the length of that line segment from the point to the line is the distance of a point to the line. Just like for regression, we can consider all lines, and for each line, calculate the average distance of the points to the line.
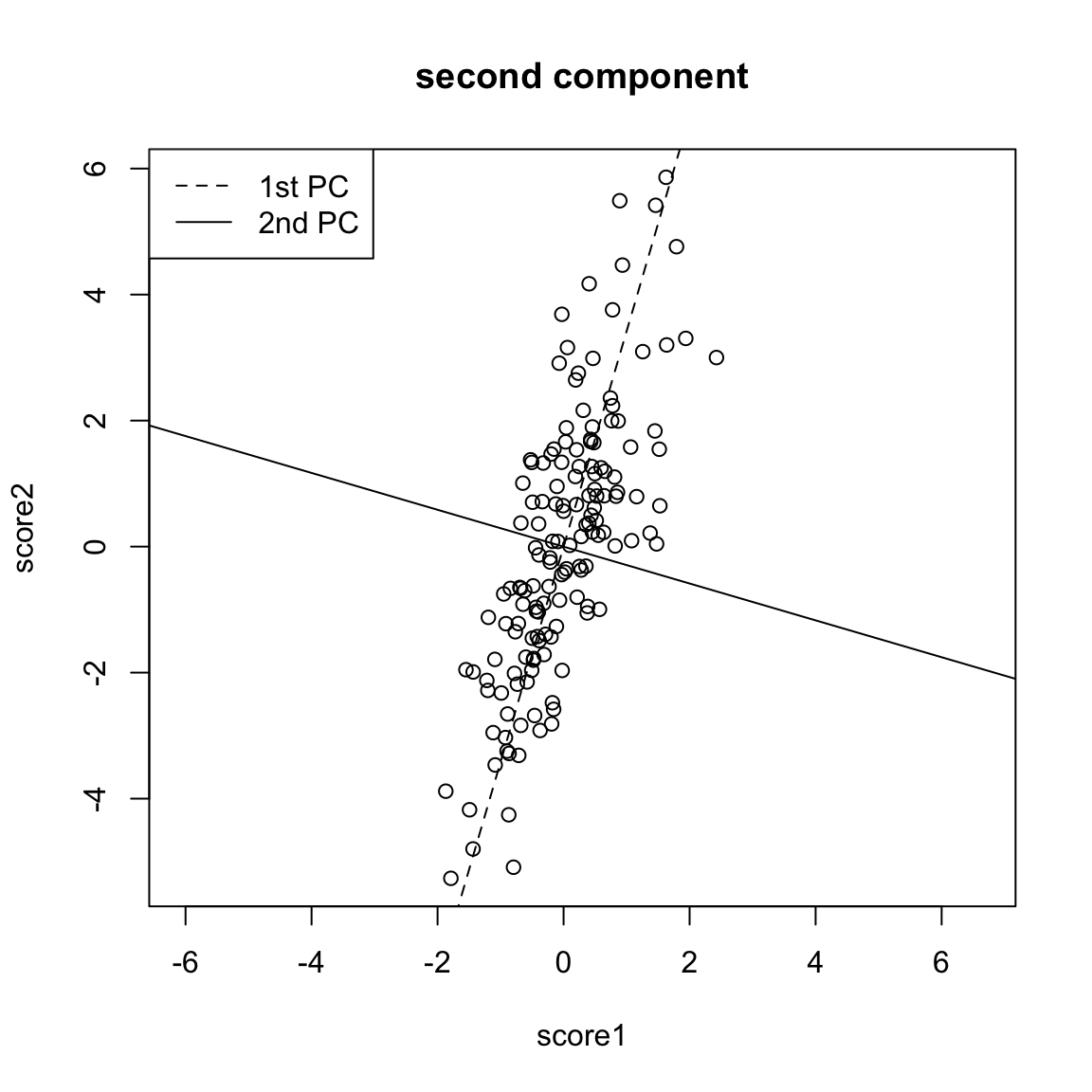
So to pick a line, we now find the line that minimizes the average distance to the line across all of the points. This is the PCA line:
Compare this to our regression line:
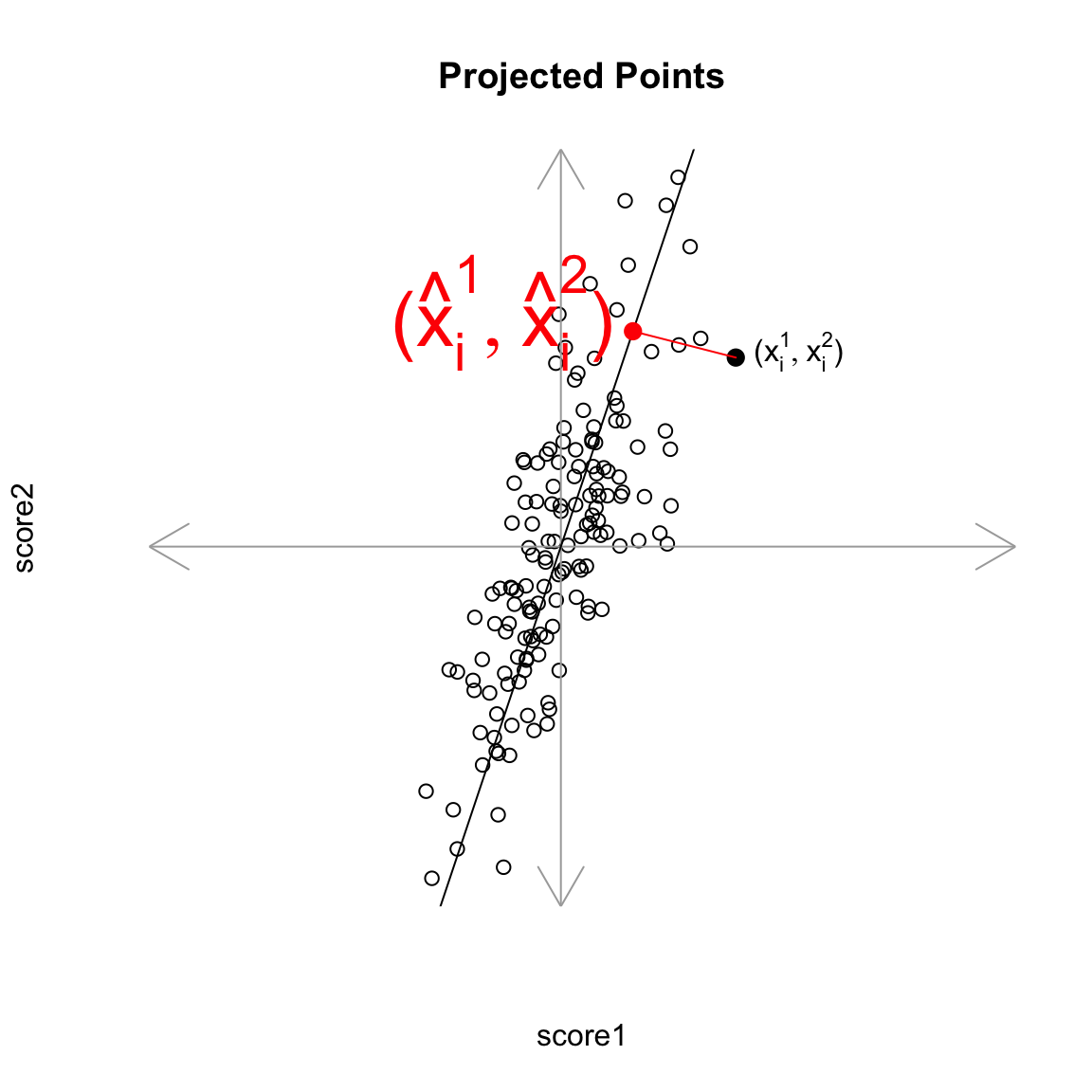
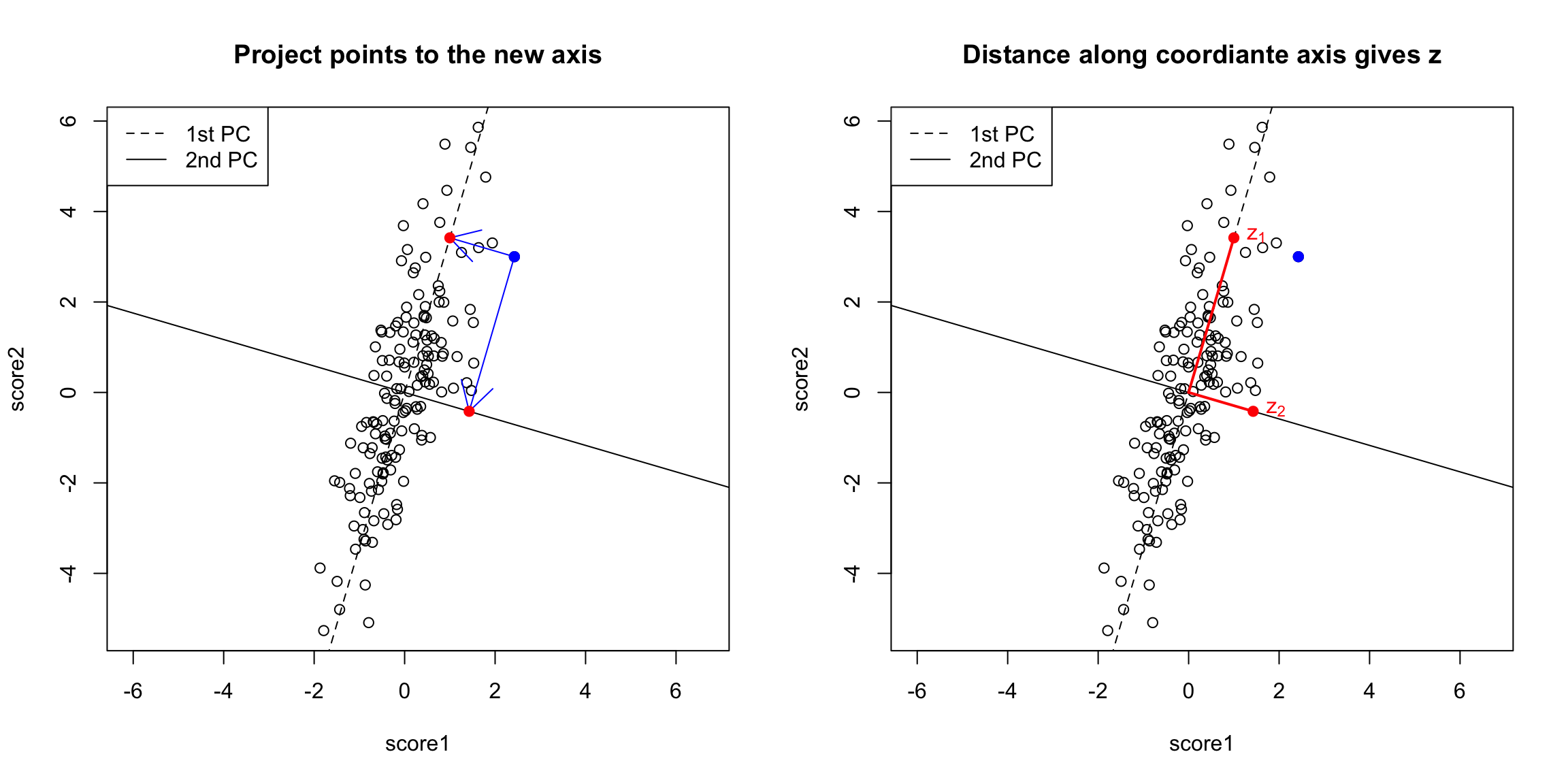
Creating a new variable from the PCA line Drawing lines through our data is all very well, but what happened to creating a new variable, that is the best summary of our two variables? In regression, we could view that our regression line gave us the “best” prediction of the average \(y\) for an \(x\) (we called it our predicted value, or \(\hat{y}\)). This best value was where our error line drawn from \(y_i\) to the regression line (vertically) intersected. Similarly, we used lines drawn from our data point to our PCA line to define the best line summary, only we’ve seen that for PCA we are interested in the line orthogonal to our point so as to be symmetric between our two variables – i.e. not just in the \(y\) direction. In a similar way, we can say that the point on the line where our perpendicular line hits the PCA line is our best summary of the value of our point. This is called the orthogonal projection of our point onto the line. We could call this new point \((\hat{x}^{(1)},\hat{x}^{(2)}\). This doesn’t actually give us a single variable in place of our original two variables, since this point is defined by 2 coordinates as well. Specifically, for any line \(x^{(2)}=a+b x^{(1)}\), we have that the coordinates of the projection onto the line are given by \[\begin{gather*} \hat{x}^{(1)}=\frac{b}{b^2+1}(\frac{x^{(1)}}{b}+x^{(2)}-a)\\ \hat{x}^{(2)}=\frac{1}{b^2+1}(b x^{(1)} + b^2 x^{(2)} + a) \end{gather*}\] (and since we’ve centered our data, we want our line to go through \((0,0)\), so \(a=0\))
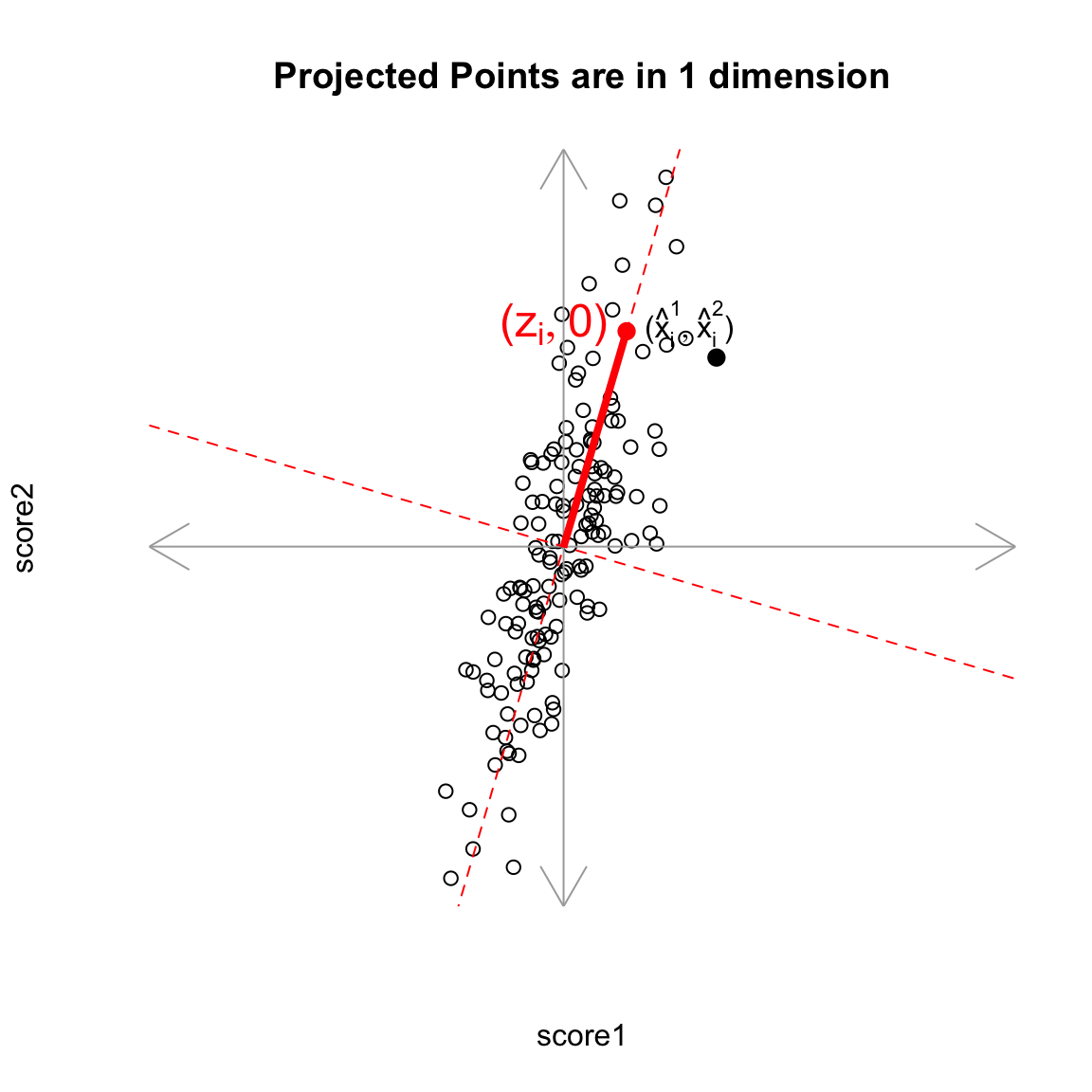
But geometrically, if we consider the points \((\hat{x}_i^{(1)},\hat{x}_i^{(2)})\) as a summary of our data, then we don’t actually need two dimensions to describe these summaries. From a geometric point of view, our coordinate system is arbitrary for describing the relationship of our points. We could instead make a coordinate system where one of the coordiantes was the line we found, and the other coordinate the orthogonal projection of that. We’d see that we would only need 1 coordinate (\(z_i\)) to describe \((\hat{x}_i^{(1)},\hat{x}_i^{(2)})\) – the other coordinate would be 0.
That coordiante, \(z_i\), would equivalently, from a geometric perspective, describe our projected points. And the value \(z_i\) is found as the distance of the projected point along the line (from \((0,0)\)). So we can consider \(z_i\) as our new variable.
Relationship to linear combinations Is \(z_i\) a linear combination of our original \(x^{(1)}\) and \(x^{(2)}\)? Yes. In fact, as a general rule, if a line going through \((0,0)\) is given by \(x^{(2)}=b x^{(1)}\), then the distance along the line of the projection is given by \[z_i = \frac{1}{\sqrt{1+b2}} (x^{(1)} + b x^{(2)})\]
Relationship to variance interpretation Finding \(z_i\) from the geometric procedure described above (finding line with minimimum orthogonal distance to points, then getting \(z_i\) from the projection of the points on to the line) is actually mathematically equivalent to finding the linear combination \(z_i=a_1 x^{(1)}+a_2 x^{(2)}\) that results in the greatest variance of our points. In other words, finding \(a_1, a_2\) to minimize \(\hat{var}(z_i)\) is the same as finding the slope \(b\) that minimizes the average distance of \((x_i^{(1)},x_i^{(2)})\) to its projected point \((\hat{x}_i^{(1)},\hat{x}_i^{(2)})\). To think why this is true, notice that if I assume I’ve centered my data, as I’ve done above, then the total variance in my two variables (i.e. sum of the variances of each variable) is given by \[\begin{gather*}\frac{1}{n-1}\sum_i (x_i^{(1)})^2 +\frac{1}{n-1}\sum_i (x_i^{(2)})^2 \\ \frac{1}{n-1}\sum_i \left[(x_i^{(1)})^2 +(x_i^{(2)})^2\right] \end{gather*}\] So that variance is a geometrical idea once you’ve centered the variables – the sum of the squared length of the vector \(((x_i^{(1)},x_i^{(2)})\). Under the geometric interpretation your new point \((\hat{x}_i^{(1)},\hat{x}_i^{(2)})\), or equivalently \(z_i\), has mean zero too, so the total variance of the new points is given by \[\frac{1}{n-1}\sum_i z_i^2\] Since we know that we have an orthogonal projection then we know that the distance \(d_i\) from the point \((x_i^{(1)},x_i^{(2)})\) to \((\hat{x}_i^{(1)},\hat{x}_i^{(2)})\) satisfies the Pythagorean theorem, \[z_i(b)^2 + d_i(b)^2 = [x_i^{(1)}]^2 + [x_i^{(2)}]^2.\] That means that finding \(b\) that minimizes \(\sum_i d_i(b)^2\) will also maximize \(\sum_i z_i(b)^2\) because \[\sum_i d_i(b)^2= \text{constant} - \sum_i z_i(b)^2\] so minimizing the left hand size will maximize the right hand side. Therefore since every \(z_i(b)\) found by projecting the data to a line through the origin is a linear combination of \(x_i^{(1)},x_i^{(2)}\) AND minimizing the squared distance results in the \(z_i(b)\) having maximum variance across all such \(z_i^2(b)\), then it MUST be the same \(z_i\) we get under the variance-maximizing procedure. The above explanation is to help give understanding of the mathematical underpinnings of why they are equivalent. But the important take-home fact is that both of these procedures are the same: if we minimize the distance to the line, we also find the linear combination so that the projected points have the most variance (i.e. we can spread out the points the most).
Compare to Mean We can use the geometric interpretation to consider what is the line corresponding to the linear combination defined by the mean, \[\frac{1}{2} x^{(1)}+\frac{1}{2} x^{(2)}\] It is the line \(y=x\),
We could see geometrically how the mean is not a good summary of our cloud of data points.
Note on Standardizing the Variables You might say, “Why not standardize your scores by the standard deviation so they are on the same scale?” For the case of combining 2 scores, if I normalized my variables, I would get essentially the same \(z\) from the PCA linear combination and the mean. However, as we will see, we can extend PCA summarization to an arbitrary number of variables, and then the scaling of the variables does not have this equivalency with the mean. This is just a freak thing about combining 2 variables.
Why maximize variance – isn’t that wrong? This geometric interpretation allows us to go back to this question we addressed before – why maximize variance? Consider this simple simulated example where there are two groups that distinguish our observations. Then the difference in the groups is creating a large spread in our observations. Capturing the variance is capturing these differences.
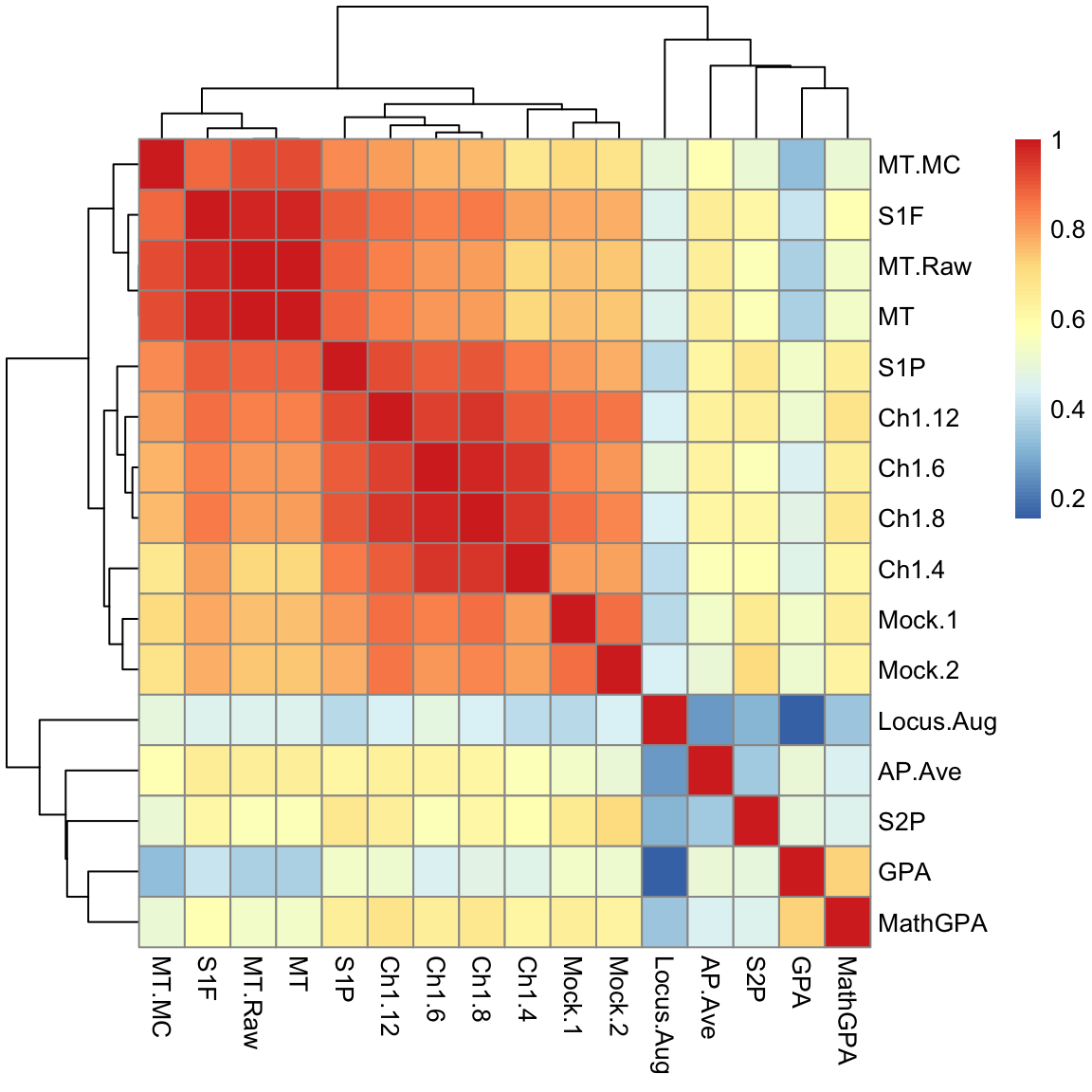
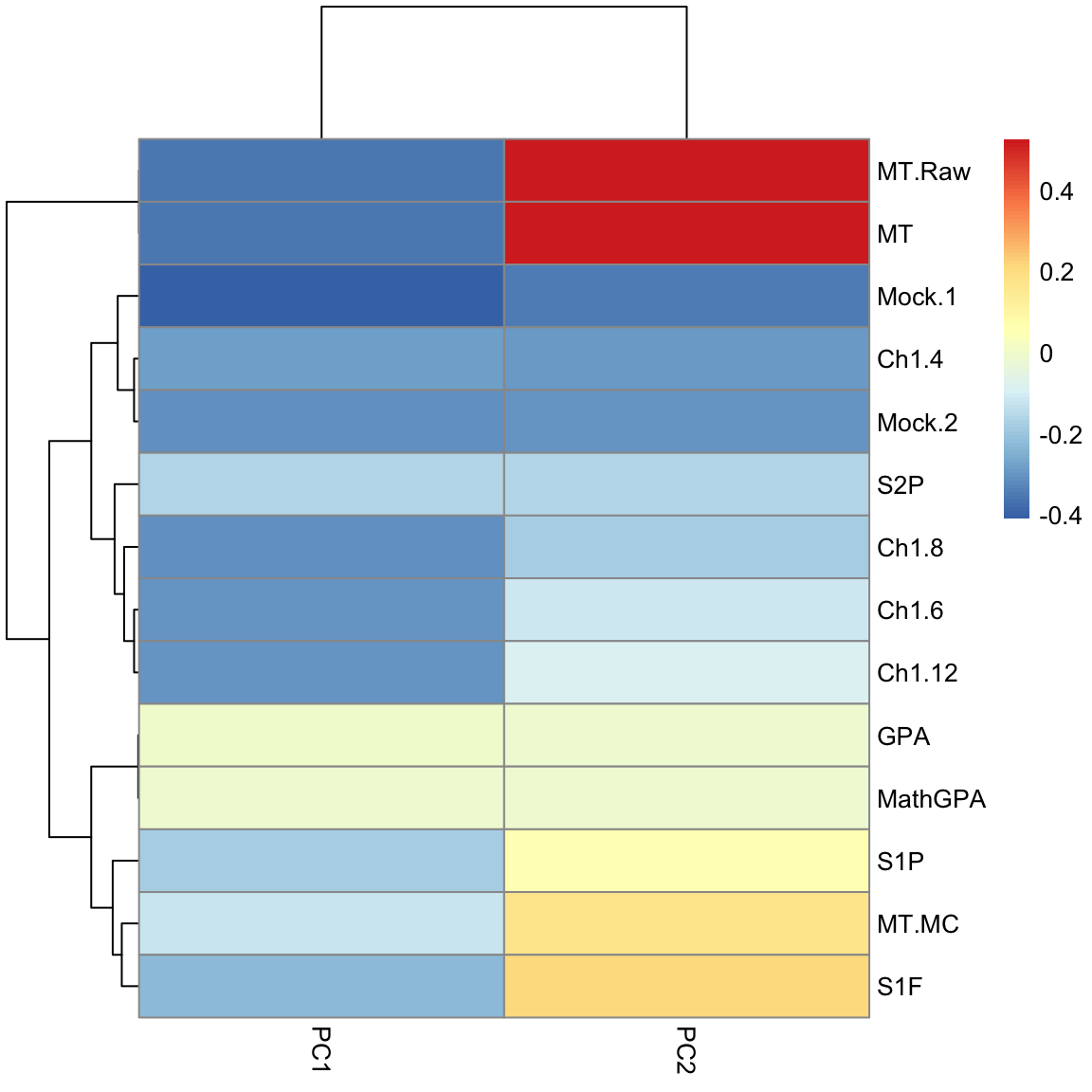
Example on real data We will look at data on scores of students taking AP statistics. First we will draw a heatmap of the pair-wise correlation of the variables.
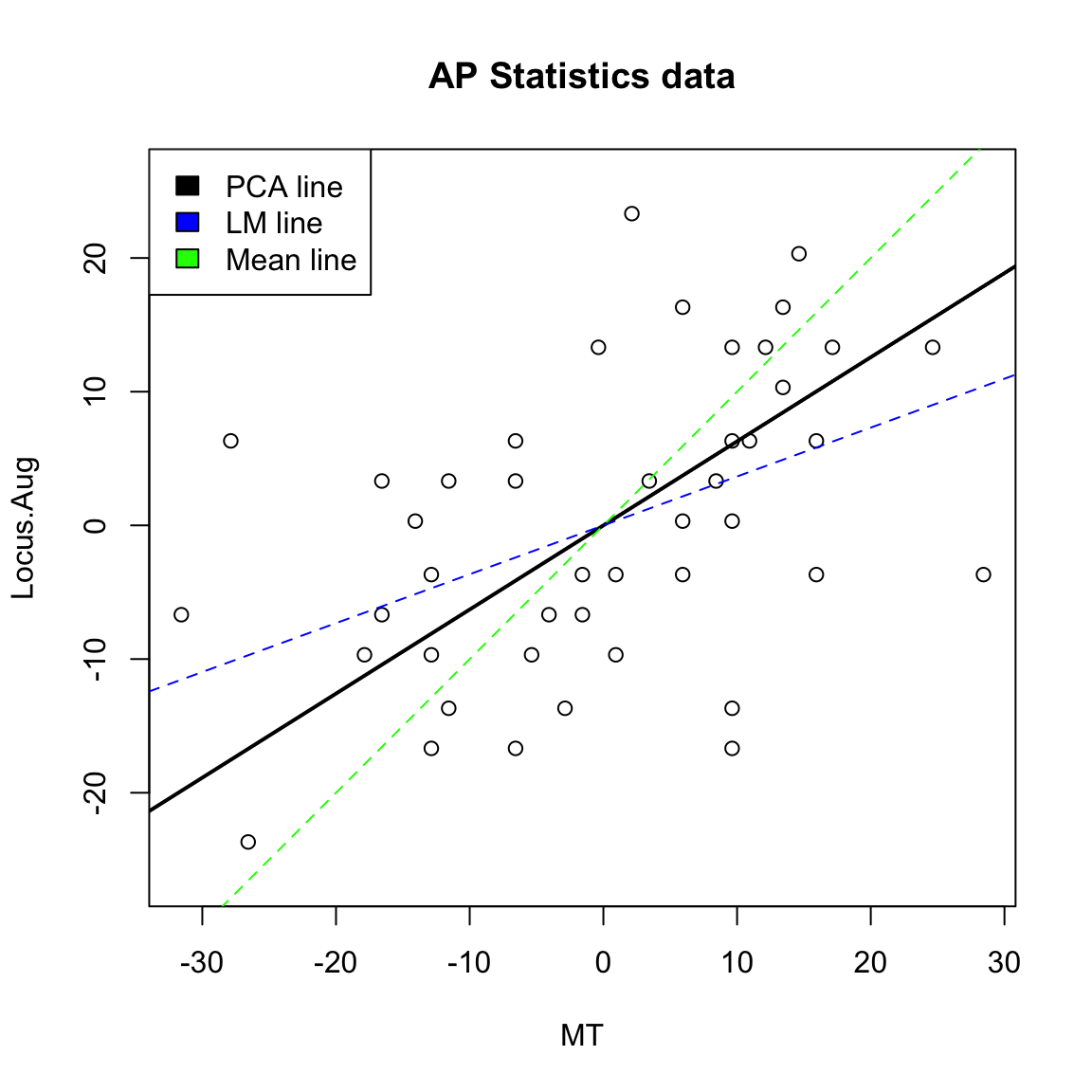
Not surprisingly, many of these measures are highly correlated. Let’s look at 2 scores, the midterm score (MT) and the pre-class evaluation (Locus.Aug) and consider how to summarize them using PCA.
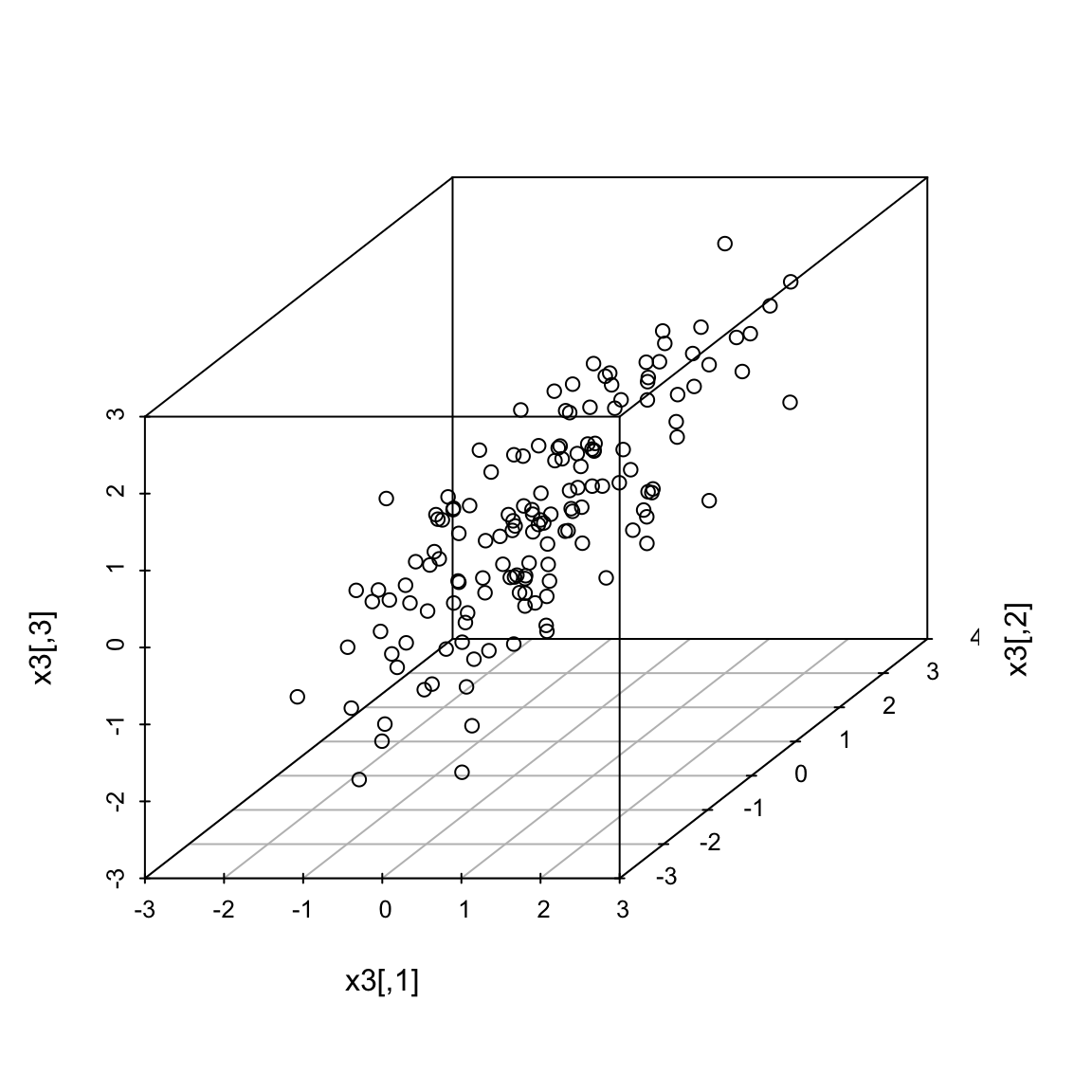
5.4.2.1 More than 2 variables We could similarly combine three measurements. Here is some simulated test scores in 3 dimensions.
Now a good summary of our data would be a line that goes through the cloud of points. Just as in 2 dimensions, this line corresponds to a linear combination of the three variables. A line in 3 dimensions is written in it’s standard form as: \[c=b_1x_i^{(1)}+b_2 x_i^{(2)}+b_3 x_i^{(3)}\] Since again, we will center our data first, the line will be with \(c=0\). The exact same principles hold. Namely, that we look for the line with the smallest average distance to the line from the points. Once we find that line (drawn in the picture above), our \(z_i\) is again the distance from \(0\) of our point projected onto the line. The only difference is that now distance is in 3 dimensions, rather than 2. This is given by the Euclidean distance, that we discussed earlier. Just like before, this is exactly equivalent to setting \(z_i= a_1x_i^{(1)}+a_2 x_i^{(2)}+a_3 x_i^{(3)}\) and searching for the \(a_i\) that maximize \(\hat{var}(z_i)\).
Many variables We can of course expand this to as many variables as we want, but it gets hard to visualize the geometric version of it. The variance-maximizing version is easier to write out. 5.4.2.2 Adding another principal component What if instead my three scores look like this (i.e. line closer to a plane than a line)?
I can get one line through the cloud of points, corresponding to my best linear combination of the three variables. But I might worry whether this really represented my data, since as we rotate the plot around we can see that my points appear to be closer to a lying near a plane than a single line.
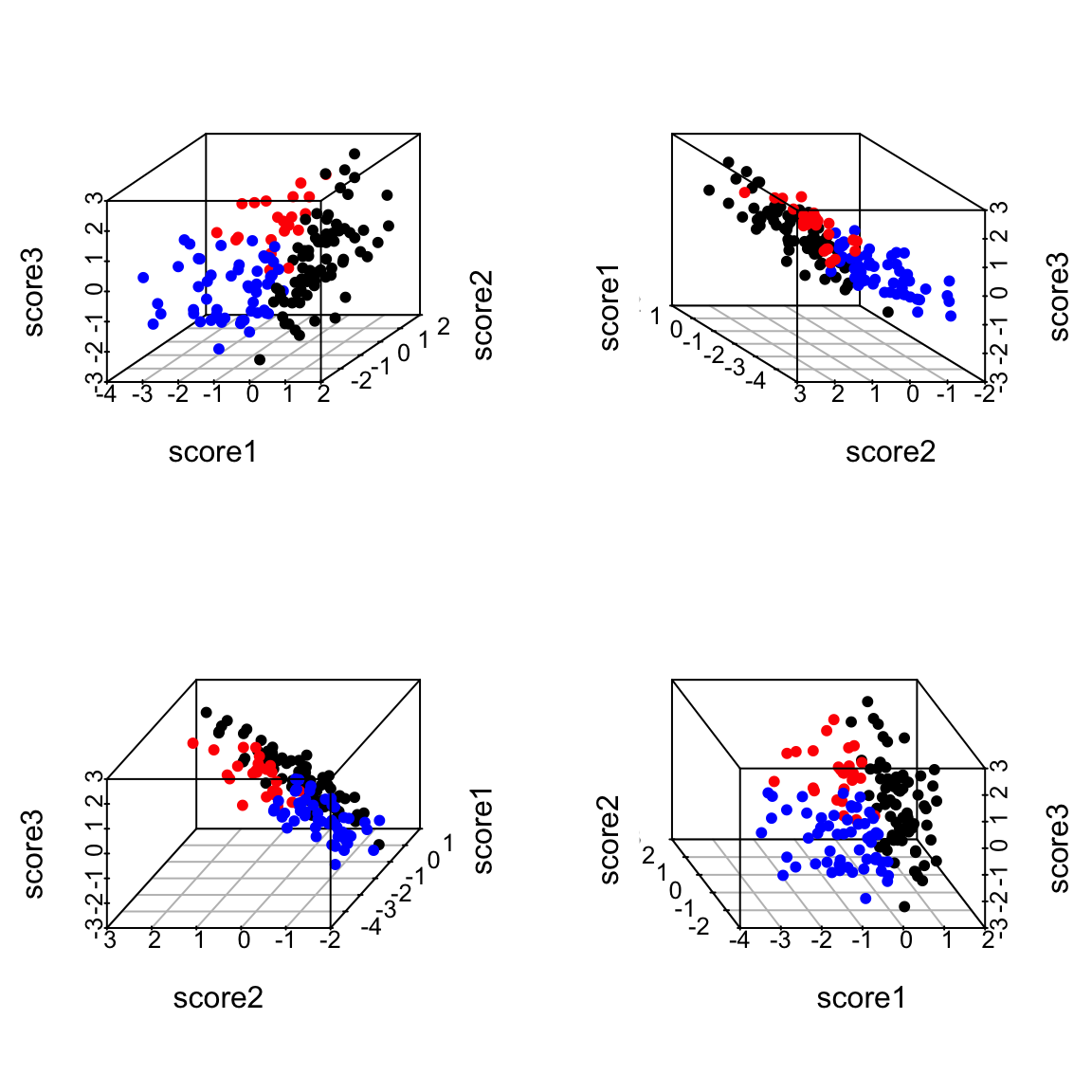
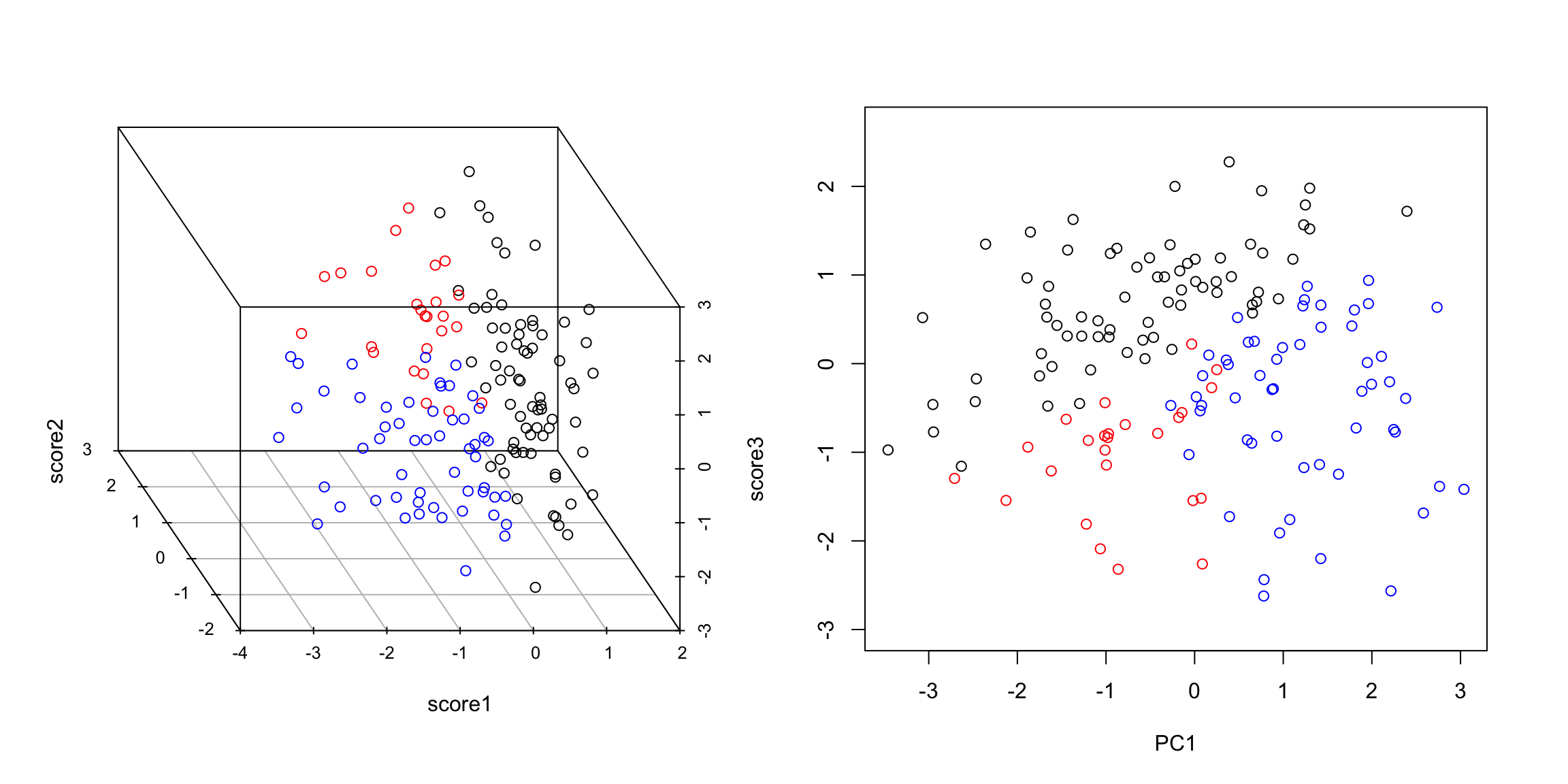
For example, can you find a single line so that if you projected your data onto that line, you could separate the three groups shown? So there’s some redundancy, in the sense that I don’t need three dimensions to geometrically represent this data, but it’s not clear that with only 1 new variable (i.e. line) we can summarize this cloud of data geometrically. 5.4.2.3 The geometric idea I might ask whether I could better summarize these three variables by two variables, i.e. as a plane. I can use the same geometric argument – find the best plane, so that the orthogonal projection of the points to the plane is the smallest. This is equivalent to finding two lines, rather than one, since a plane can be defined by any two lines that lie on it. I could just search for the plane that is closest to the points, just like previously I searched for a line that is closest to the points – i.e. any two lines on the plane will do, so long as I get the right plane. But that just gives me the plane. It doesn’t give me new data points. To do that, I need coordiantes of each point projected onto the plane, like previously we projected onto the line. I need to set up an orthogonal coordinate axis so I can define \((z_i^{(1)},z_i^{(2)})\) for each point.
Thus the new points \((z_i^{(1)},z_i^{(2)})\) represent the points after being projected on to that plane in 3d. So we can summarize the 3 dimensional cloud of points by this two dimensional cloud. This is now a summary of the 3D data. Which is nice, since it’s hard to plot in 3D. Notice, I can still see the differences between my groups, so I have preserved that important variability (unlike using just a single line):
5.4.2.4 Finding the Best Plane I want to be smarter than just finding any coordinate system for my “best” plane – there is an infinite number of equivalent choices. So I would like the new coordinates \((z_i^{(1)},z_i^{(2)})\) to be useful in the following way: I want my first coordinate \(z_i^{(1)}\) to correspond to the coordinates I would get if I just did just 1 principal component, and then pick the next coordinates to be the orthogonal direction from the 1st principal component that also lies on the plane. This reduces the problem of finding the plane to 1) finding the 1st principal component, as described above, then 2) finding the “next best” direction. So we need to consider how we find the next best direction.
Consider 2-dimensions Let’s return to our 2-dim example to consider how we can “add” another dimension to our summary. If I have my best line, and then draw another line very similar to it, but slightly different slope, then it will have very low average distance of the points to the line. And indeed, we wouldn’t be able to find “next best” in this way, because the closest to the best line would be choosen – closer and closer until in fact it is the same as the best line. Moreover, such a line that is close to the best doesn’t give me very different information from my best line. So I need to force “next best” to be separated and distinct from my best line. How do we do that? We make the requirement that the next best line be orthogonal from the best line – this matches our idea above that we want an orthogonal set of lines so that we set up a new coordinate axes. In two dimensions that’s a pretty strict constraint – there’s only 1 such line! (at least that goes through the center of the points).
Return to 3 dimensions In three dimensions, however, there are a whole space of lines to pick from that are orthogonal to the 1st PC and go through the center of the points. Not all of these lines will be as close to the data as others lines. So there is actually a choice to be made here. We can use the same criterion as before. Of all of these lines, which minimize the distance of the points to the line? Or (equivalently) which result in a linear combination with maximum variance? To recap: we find the first principal component based on minimizing the points’ distance to line. To find the second principal component, we similarly find the line that minimize the points’ distance to the line but only consider lines orthogonal to the the first component. If we follow this procedure, we will get two orthogonal lines that define a plane, and this plane is the closest to the points as well (in terms of the orthogonal distance of the points to the plane). In otherwords, we found the two lines without thinking about finding the “best” plane, but in the end the plane they create will be the closest. 5.4.2.5 Projecting onto Two Principal Components Just like before, we want to be able to not just describe the best plane, but to summarize the data. Namely, we want to project our data onto the plane. We do this again, by projecting each point to the point on the plane that has the shortest distance, namely it’s orthogonal projection. We could describe this project point in our original coordinate space (i.e. with respect to the 3 original variables), but in fact these projected points lie on a plane and so we only need two dimensions to describe these projected points. So we want to create a new coordinate system for this plane based on the two (orthogonal) principal component directions we found.
Finding the coordiantes in 2Dim Let’s consider the simple 2-d case again. Since we are in only 2D, our two principal component directions are equivalent to defining a new orthogonal coordinate system. Then the new coordinates of our points we will call \((z_i^{(1)},z_i^{(2)})\). To figure out their values coordiantes of the points on this new coordinate system, we do what we did before: Project the points onto the first direction. The distance of the point along the first direction is \(z_i^{(1)}\) Project the points onto the second direction. The distance of the point along the second direction is \(z_i^{(2)}\)
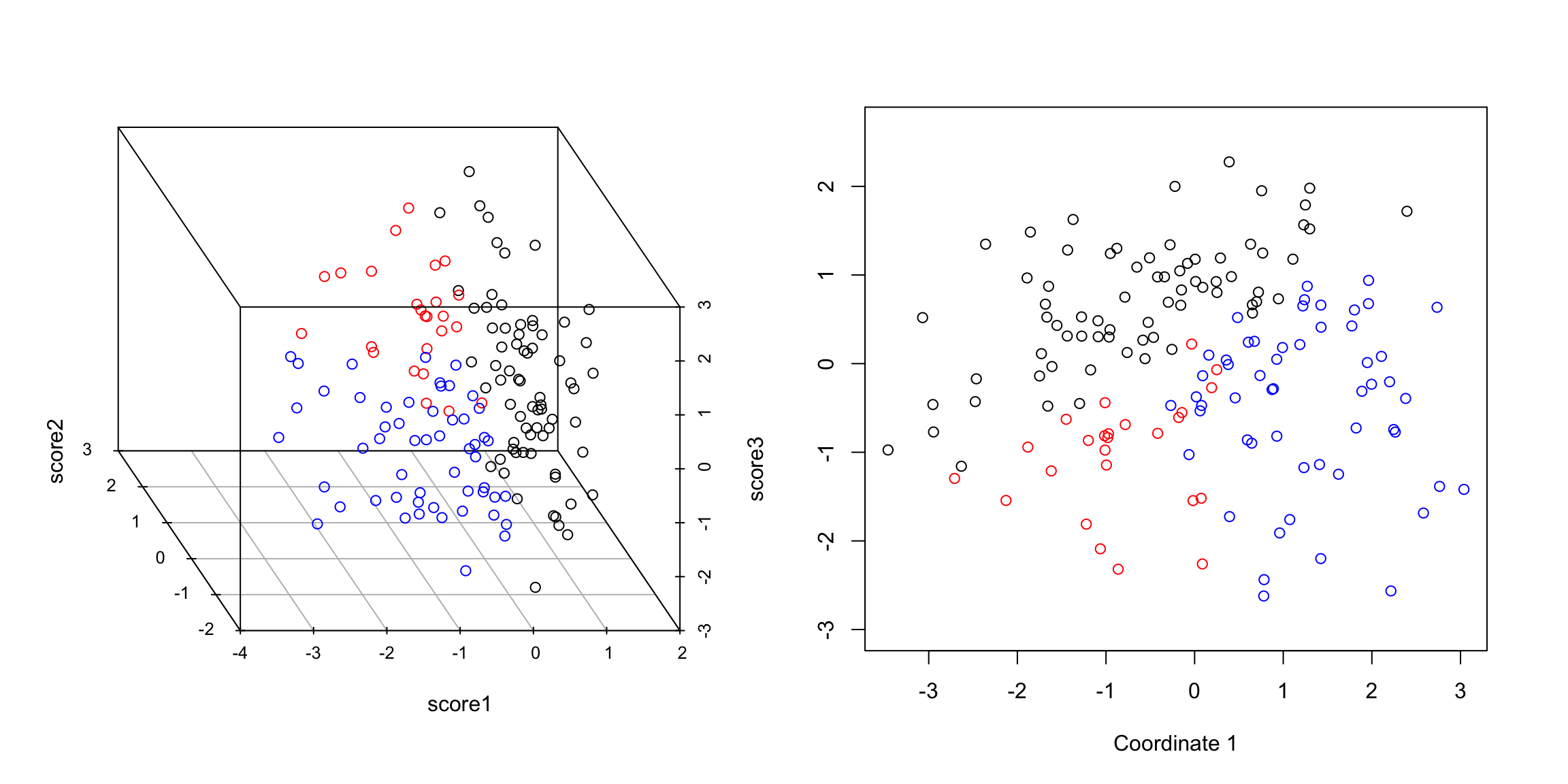
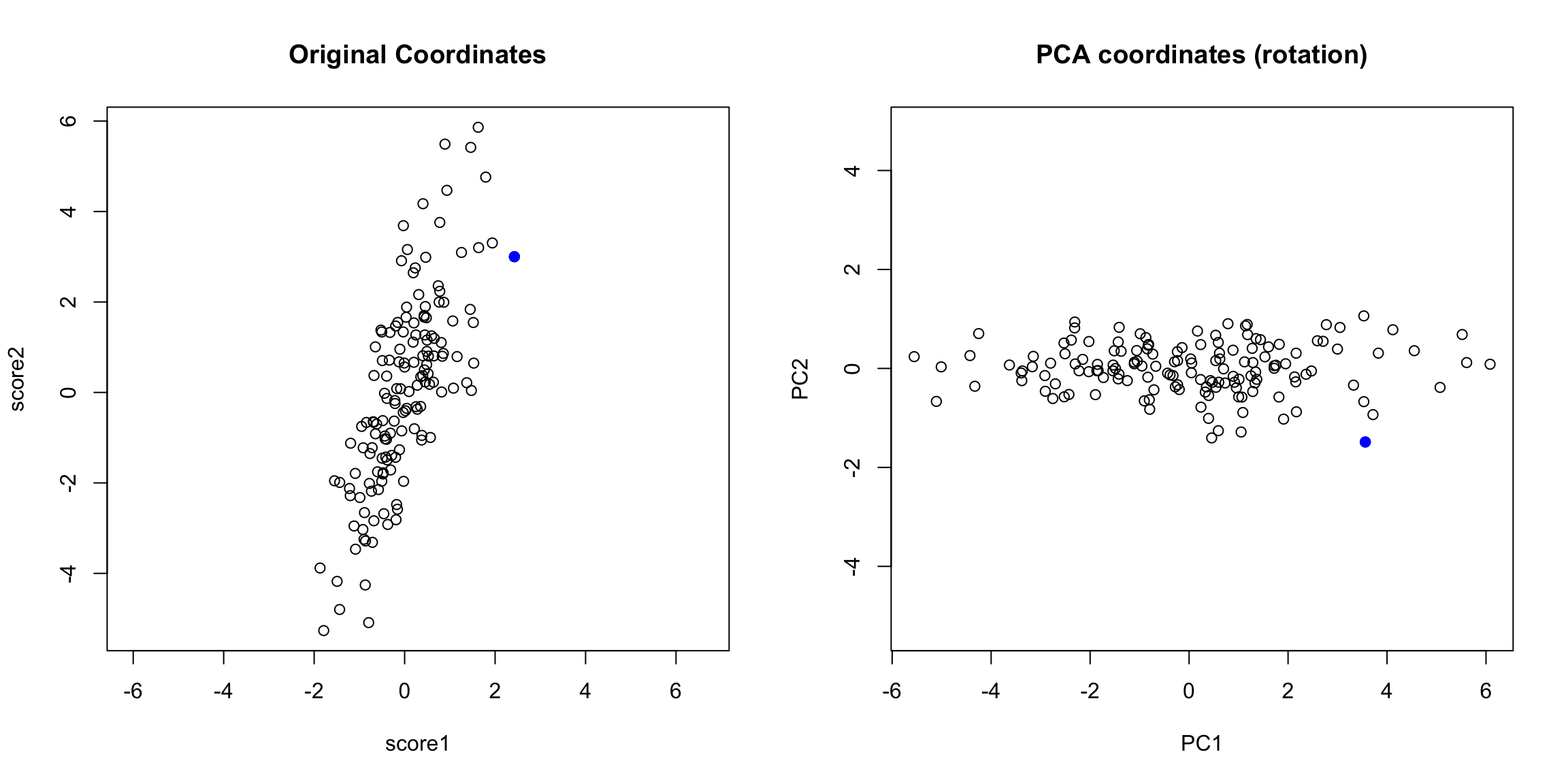
You can now consider them as new coordinates of the points. It is common to plot them as a scatter plot themselves, where now the PC1 and PC2 are the variables.
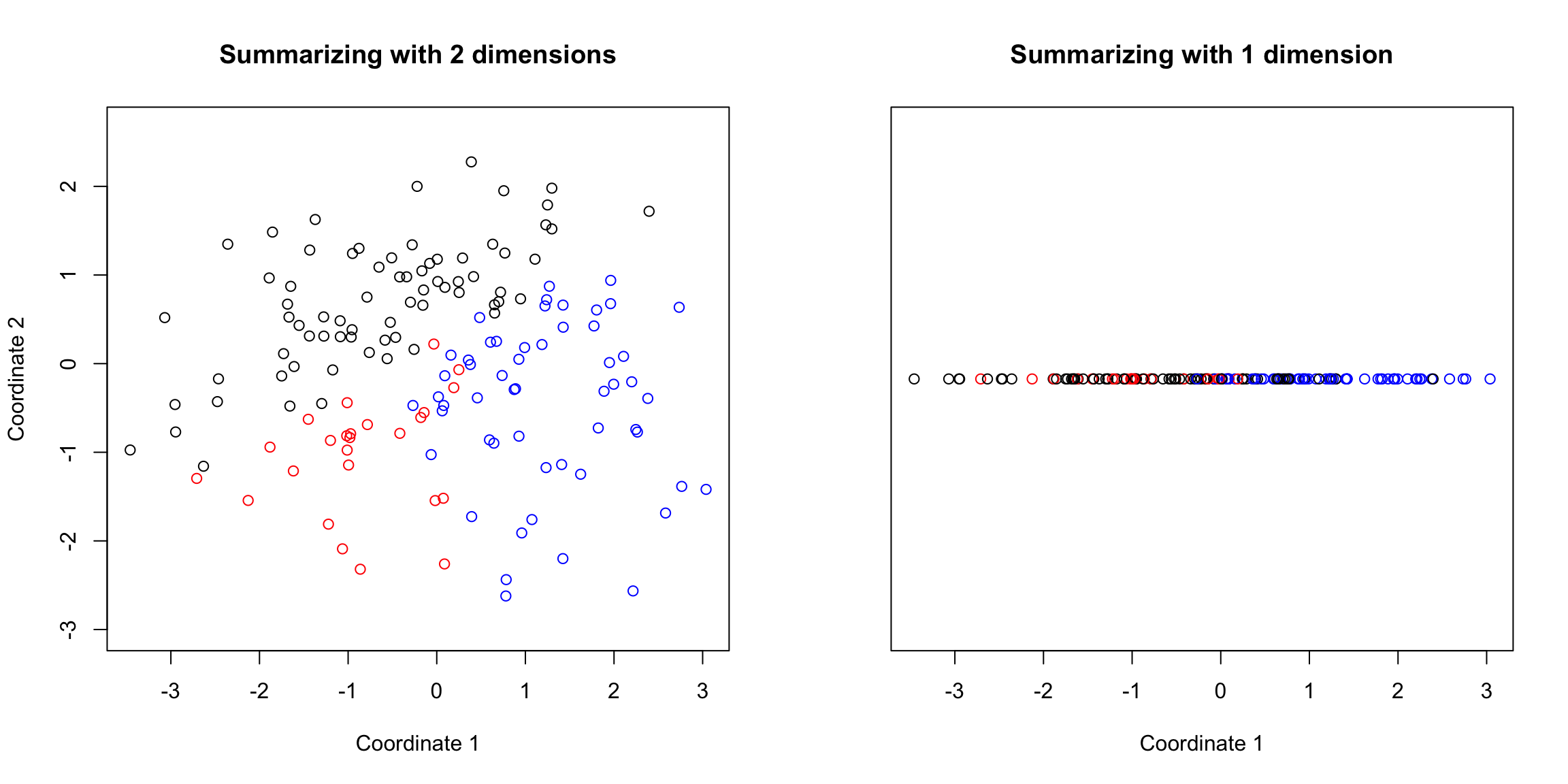
Preserving distances in 2D In two dimensions, we completely recapture the pattern of the data with 2 principal components – we’ve just rotated the picture, but the relationship of the points to each other (i.e. their distances to each other), are exactly the same. So plotting the 2 PC variables instead of the 2 original variables doesn’t tell us anything new about our data, but we can see that the relationship of our variables to each other is quite different. Of course this distance preserving wasn’t true if I projected only onto one principal component; the distances in the 1st PC variable are not the same as the distances in the whole dimension space.
3-dimensions and beyond For our points in 3 dimensions, we will do the same thing: project the data points to each of our two PC directions separately, and make \(z_i^{(1)}\) and \(z_i^{(2)}\) the distance of the projection along each PC line. These values will define a set of coordinates for our points after being projected to the best plane.
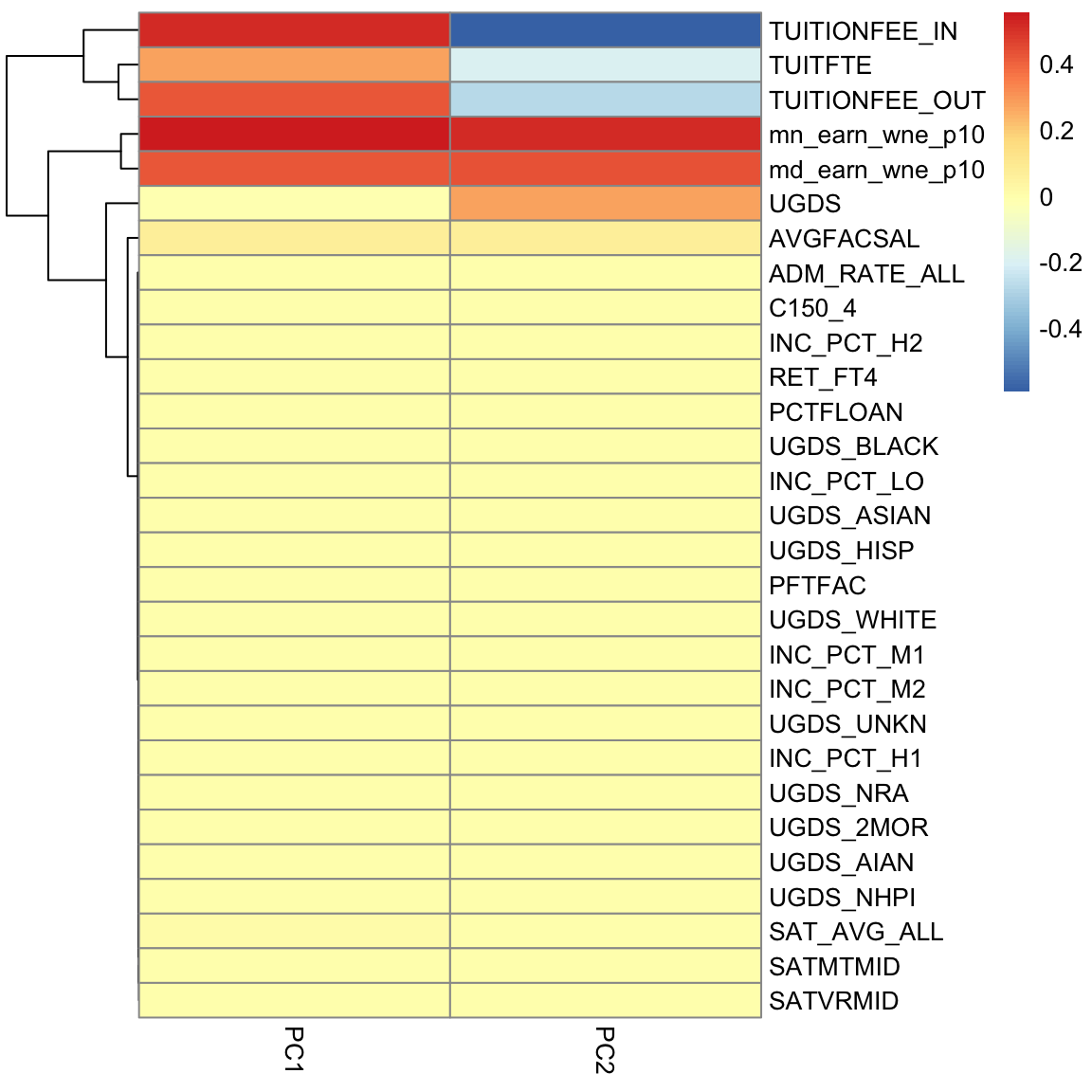
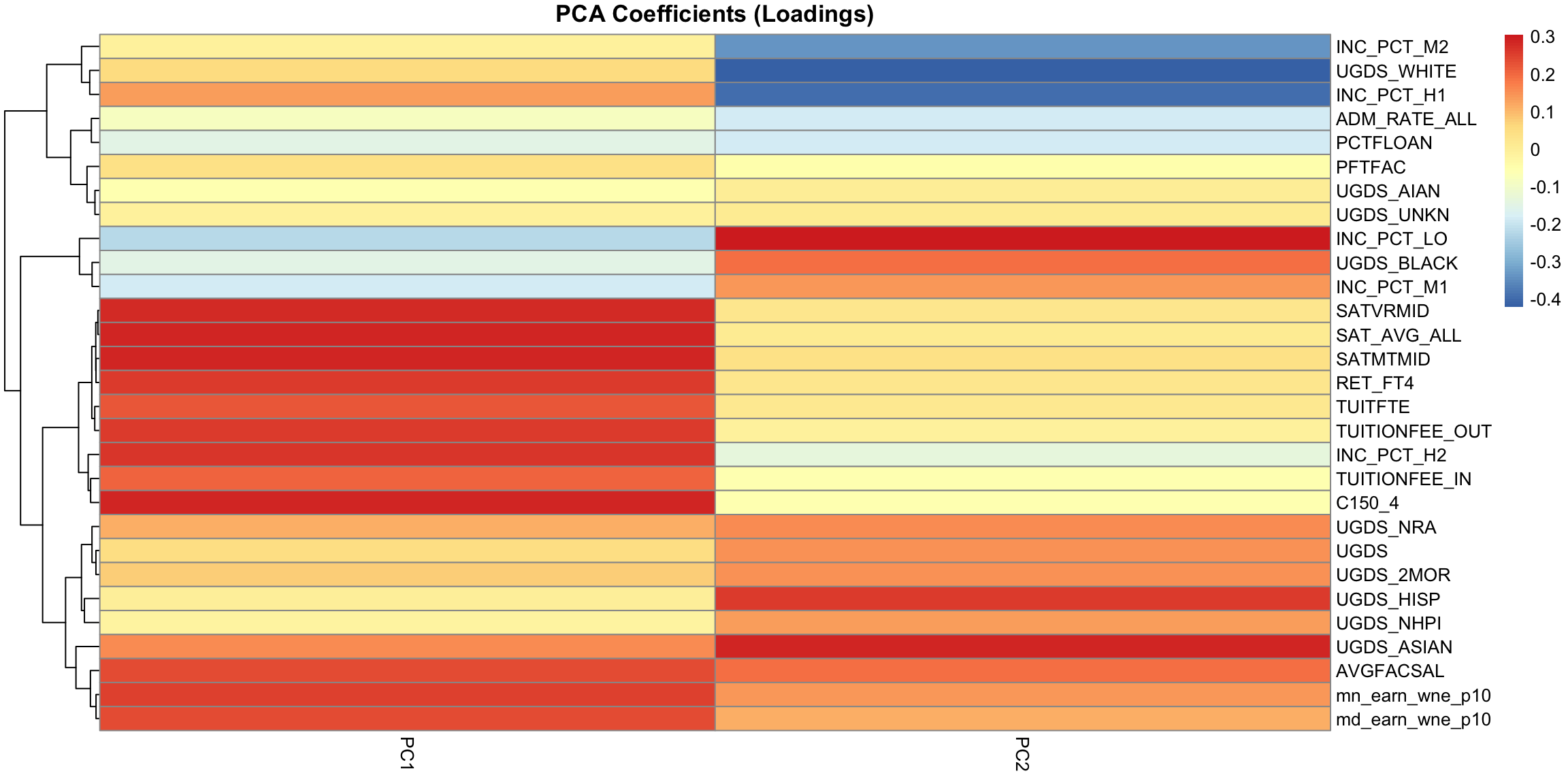
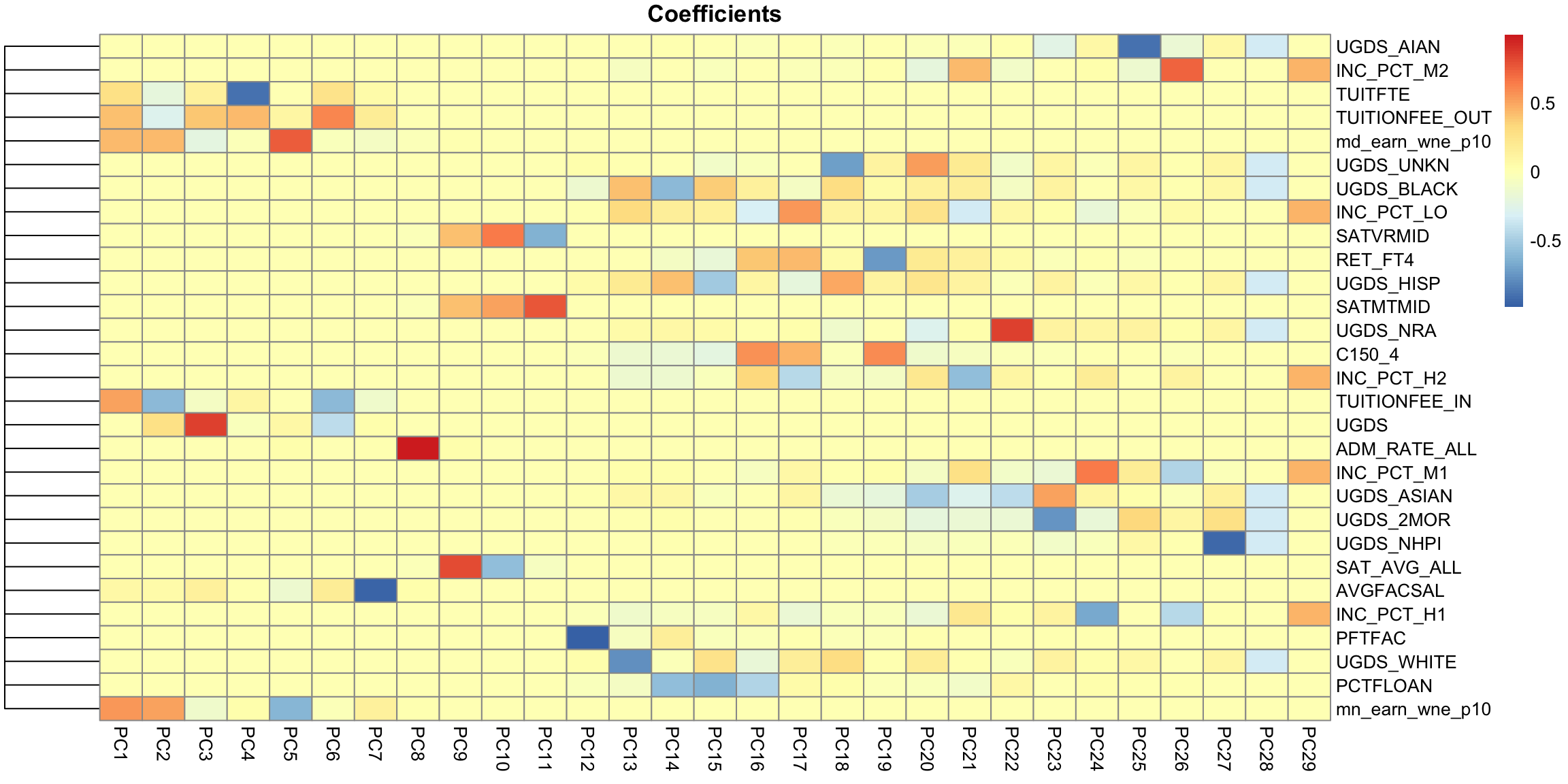
But unlike our 2D example, the projection of these points to the plane don’t preserve the entire dataset, so the plot of the data based on these two coordinates is not equivalent to their position in the 3-dimensional space. We are not representing the noise around the plane (just like in 2D, where the projection of points to the line misses any noise of the points around the line). In general, if we have less principal components than the number of original variables, we will not have a perfect recapitulation of the data. But that’s okay, because what such a plot does is summarize the 3 dimensional cloud of points by this two dimensional cloud, which captures most of the variablity of the data. Which is nice, since it’s hard to plot in 3D. 5.4.3 Interpreting PCA 5.4.3.1 Loadings The scatterplots doen’t tell us how the original variables relate to our new variables, i.e. the coefficients \(a_j\) which tell us how much of each of the original variables we used. These \(a_j\) are sometimes called the loadings. We can go back to what their coefficients are in our linear combination
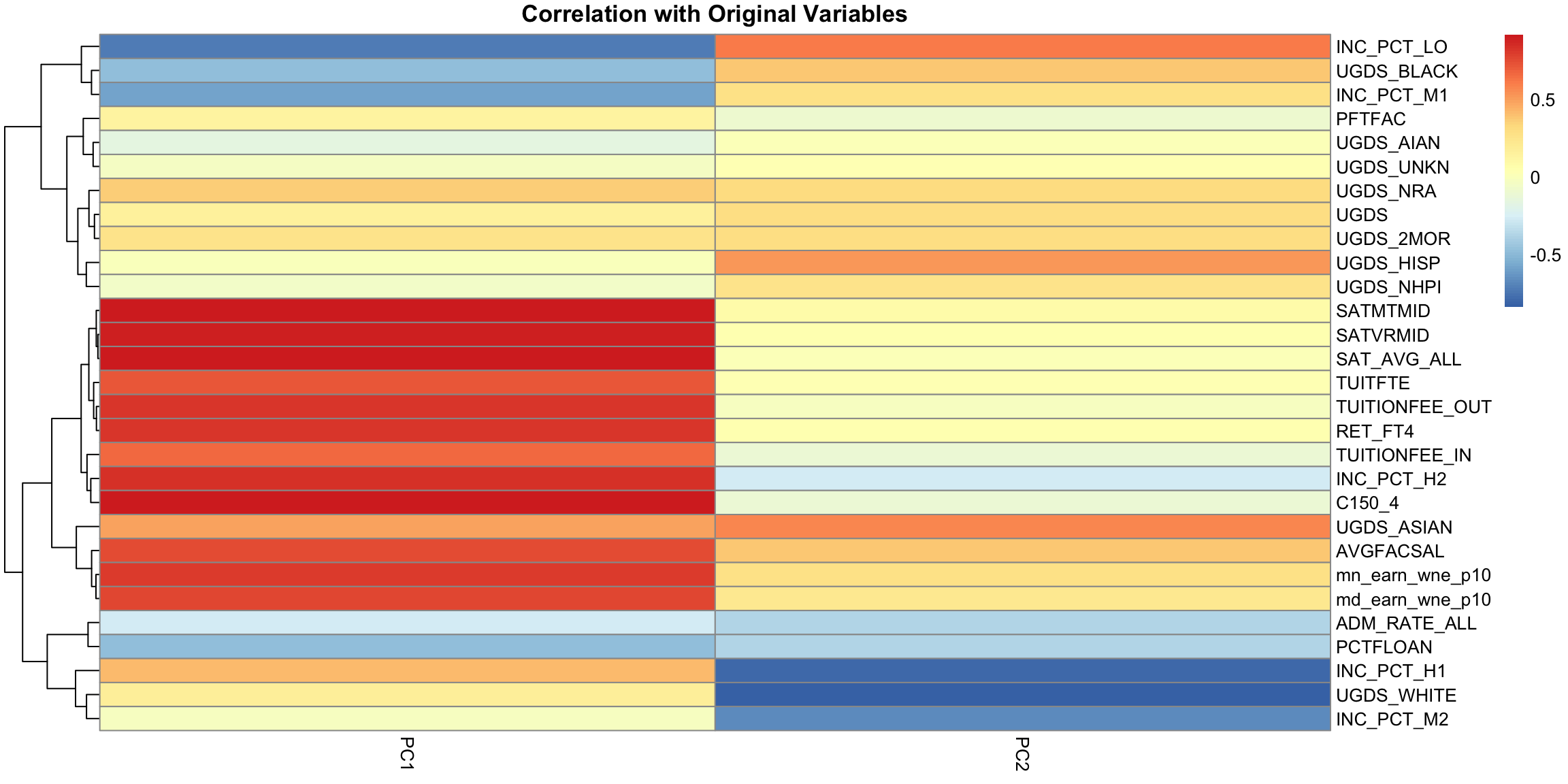
PC2, however, has negative values for the tuition related variables, and positive values for the financial aid earnings variables; and UGDS is the number of Undergraduate Students, which has also positive coefficients. So university with high tuition relative to the aggregate amount of financial aid they give and student size, for example, will have low PC2 values. This makes sense: PC2 is the variable that pretty cleanly divided private and public schools, with private schools having low PC2 values. 5.4.3.2 Correlations It’s often interesting to look at the correlation between the new variables and the old variables. Below, I plot the heatmap of the correlation matrix consisting of all the pair-wise correlations of the original variables with the new PCs corPCACollege <-cor(pcaCollege$x, scale(scorecard[-whNACollege, -c(1:3, 12)], center = TRUE, scale = FALSE)) pheatmap(corPCACollege[1:2, ], cluster_cols = FALSE, col = seqPal2)
Notice this is not the same thing as which variables contributed to PC1/PC2. For example, suppose a variable was highly correlated with tuition, but wasn’t used in PC1. It would still be likely to be highly correlated with PC1. This is the case, for example, for variables like SAT scores. 5.4.3.3 Biplot We can put information regarding the variables together in what is called a biplot. We plot the observations as points based on their value of the 2 principal components. Then we plot the original variables as vectors (i.e. arrows). par(mfrow = c(1, 2)) plot(pcaCollege$x[, 1:2], col = c("red", "black")[scorecard$CONTROL[-whNACollege]], asp = 1) legend("topright", c("public", "private"), fill = c("red", "black")) suppressWarnings(biplot(pcaCollege, pch = 19, main = "Biplot"))
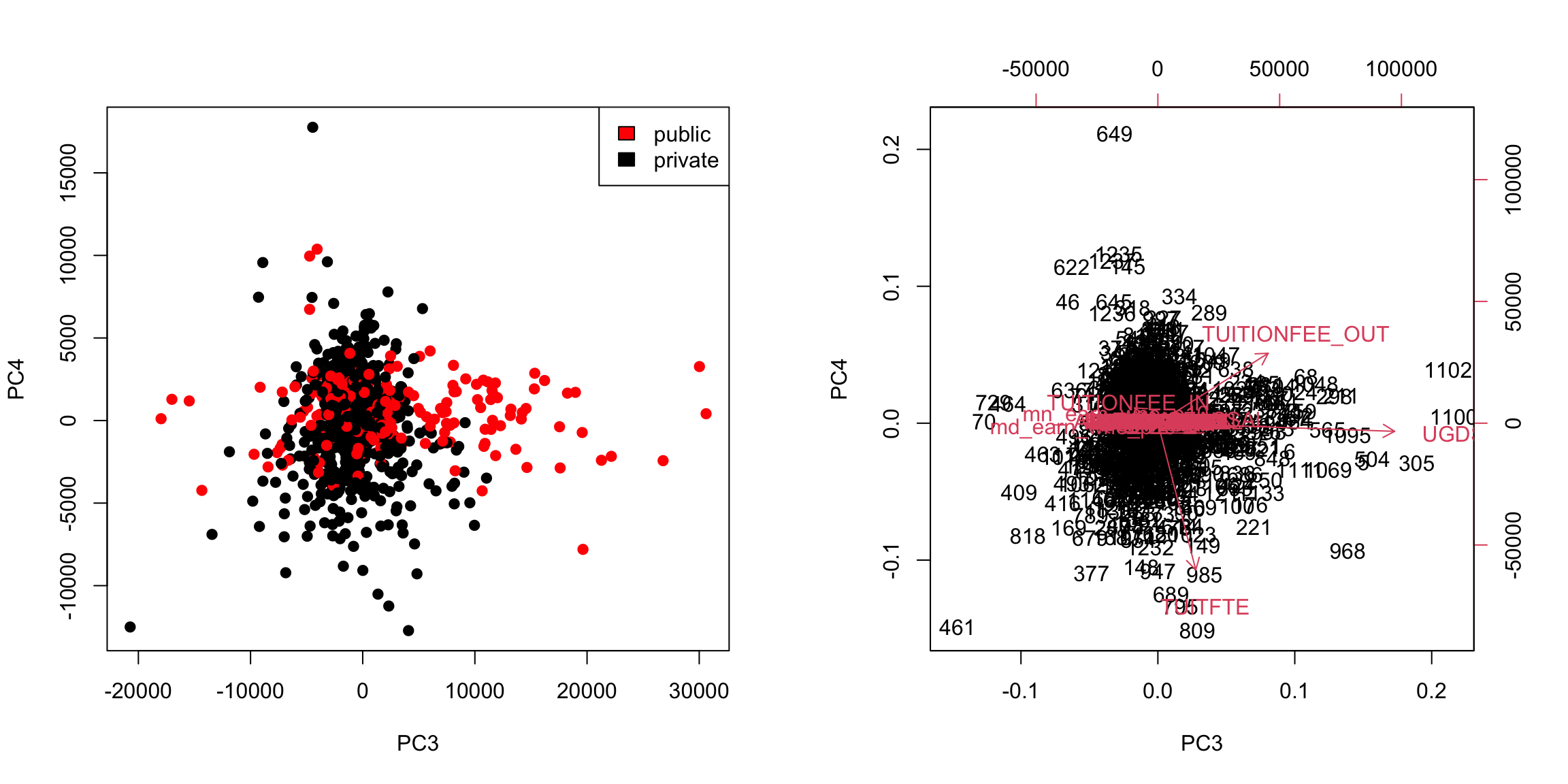
Interpretation of the Biplot The arrow for a variable points in the direction that is most like that variable. So points that are in the direction of that vector tend to have large values of that variable, while points in the opposite direction of that vector have large negative values of that variable. Vectors that point in the same direction correspond to variables where the observations show similar patterns. The length of the vector corresponds to how well that vector in this 2-dim plot actually represents the variable. So long vectors tell you that the above interpretation I gave regarding the direction of the vector is a good one, while short vectors indicate that the above interpretation is not very accurate. If we see vectors that point in the direction of one of the axes, this means that the variable is highly correlated with the principal component in that axes. I.e. the resulting new variable \(z\) that we get from the linear combination for that principal component is highly correlated with that original variable. So the variables around tuition fee, we see that it points in the direction of large PC1 scores meaning observations with large PC1 scores will have higher values on those variables (and they tend to be private schools). We can see that the number of undergraduates (UGDS) and the aggregate amount of financial aid go in positive directions on PC2, and tuition are on negative directions on PC2. So we can see that some of the same conclusions we got in looking at the loadings show up here.
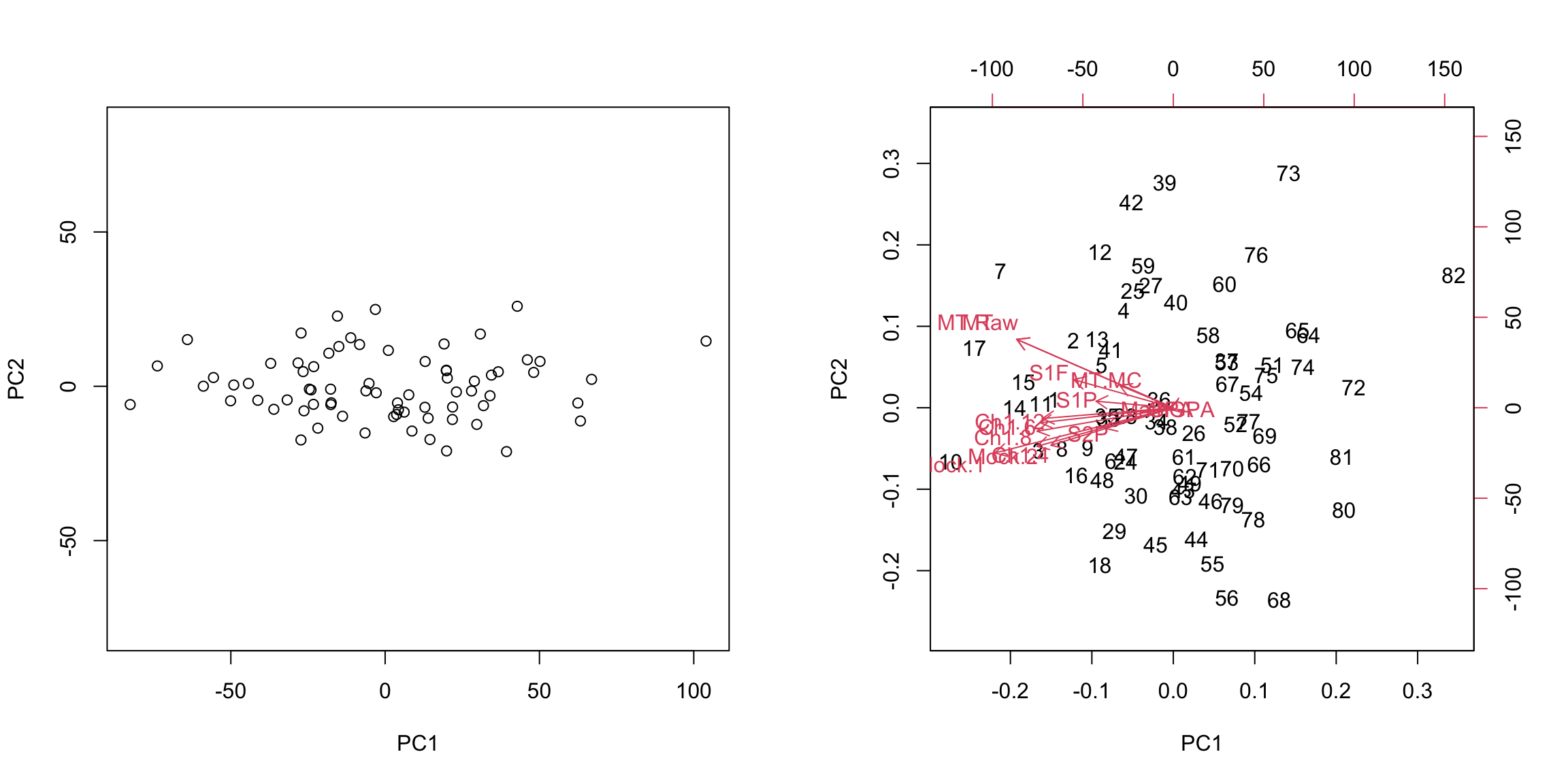
Example: AP Scores We can perform PCA on the full set of AP scores variables and make the same plots for the AP scores. There are many NA values if I look at all the variables, so I am going to remove Locus.Aug' (the score on the diagnostic taken at beginning of year) andAP.Ave’ (average on other AP tests) which are two variables that have many NAs, as well as removing categorical variables.
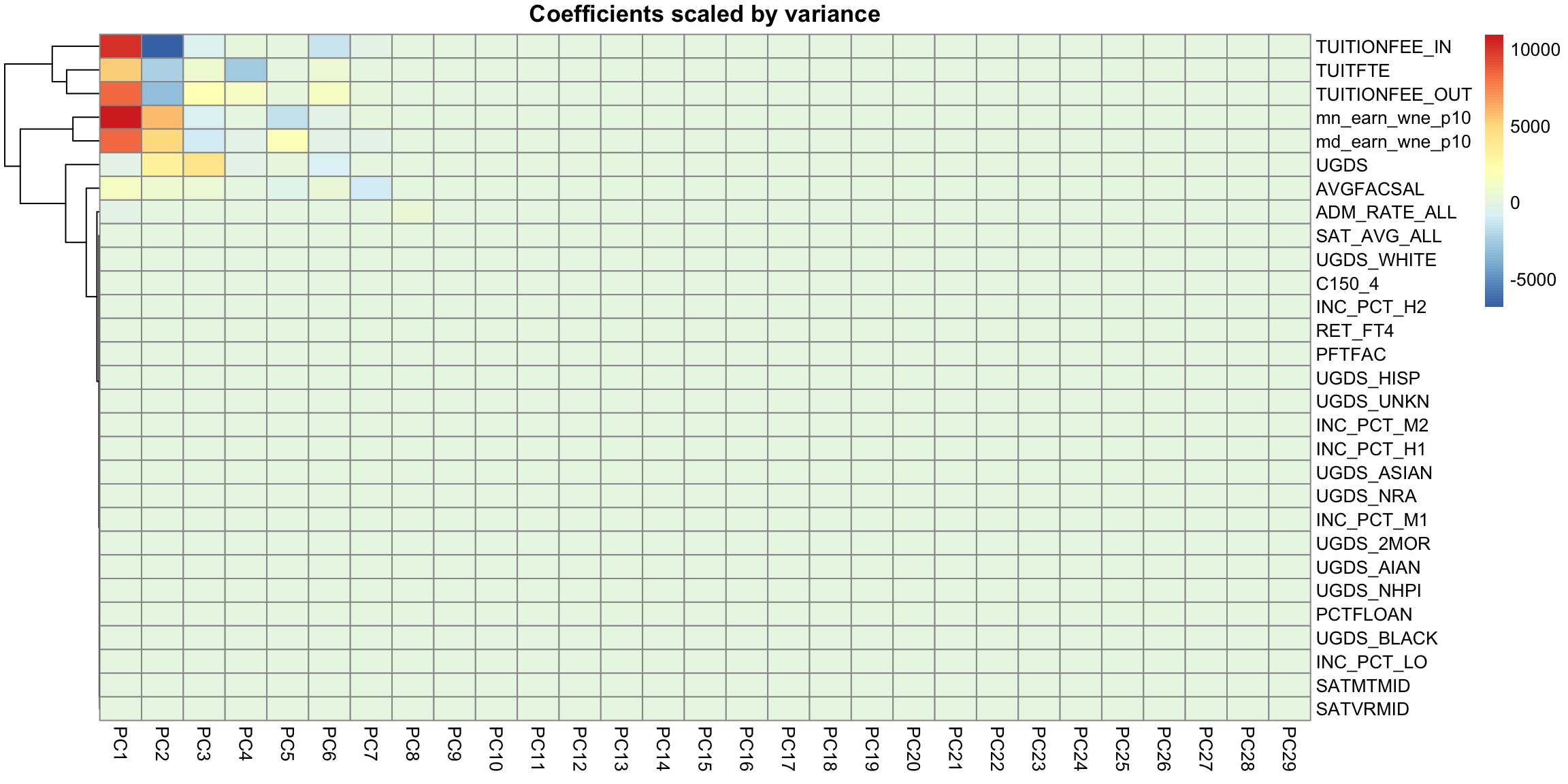
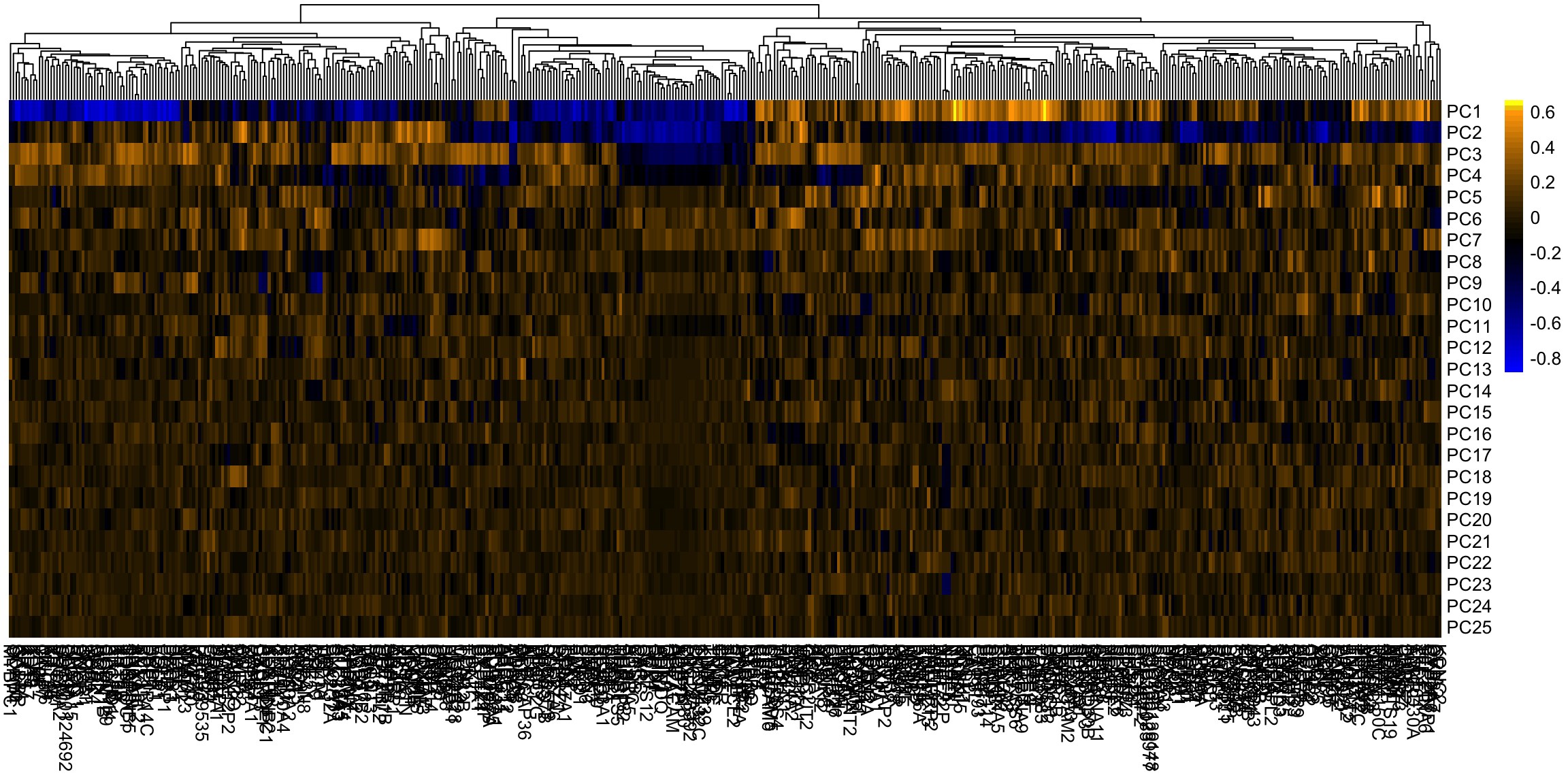
5.4.3.4 Scaling Even after centering our data, our variables are on different scales. If we want to look at the importance of variables and how to combine variables that are redundant, it is more helpful to scale each variable by its standard deviation. Otherwise, the coefficients \(a_k\) represent a lot of differences in scale of the variables, and not the redundancy in the variables. Doing so can change the PCA coordinates a lot.
There is still a slight preference for public schools to be lower on the 1st principal component, but its quite slight. We see that many more variables contribute to the first 2 PCs after scaling them.
5.4.4 More than 2 PC coordinates In fact, we can find more than 2 PC variables. We can continue to search for more components in the same way, i.e. the next best line, orthogonal to both of the lines that came before. The number of possible such principal components is equal to the number of variables (or the number of observations, whichever is smaller; but in all our datasets so far we have more observations than variables). We can plot a scatter plot of the resulting third and 4th PC variables from the college data just like before.
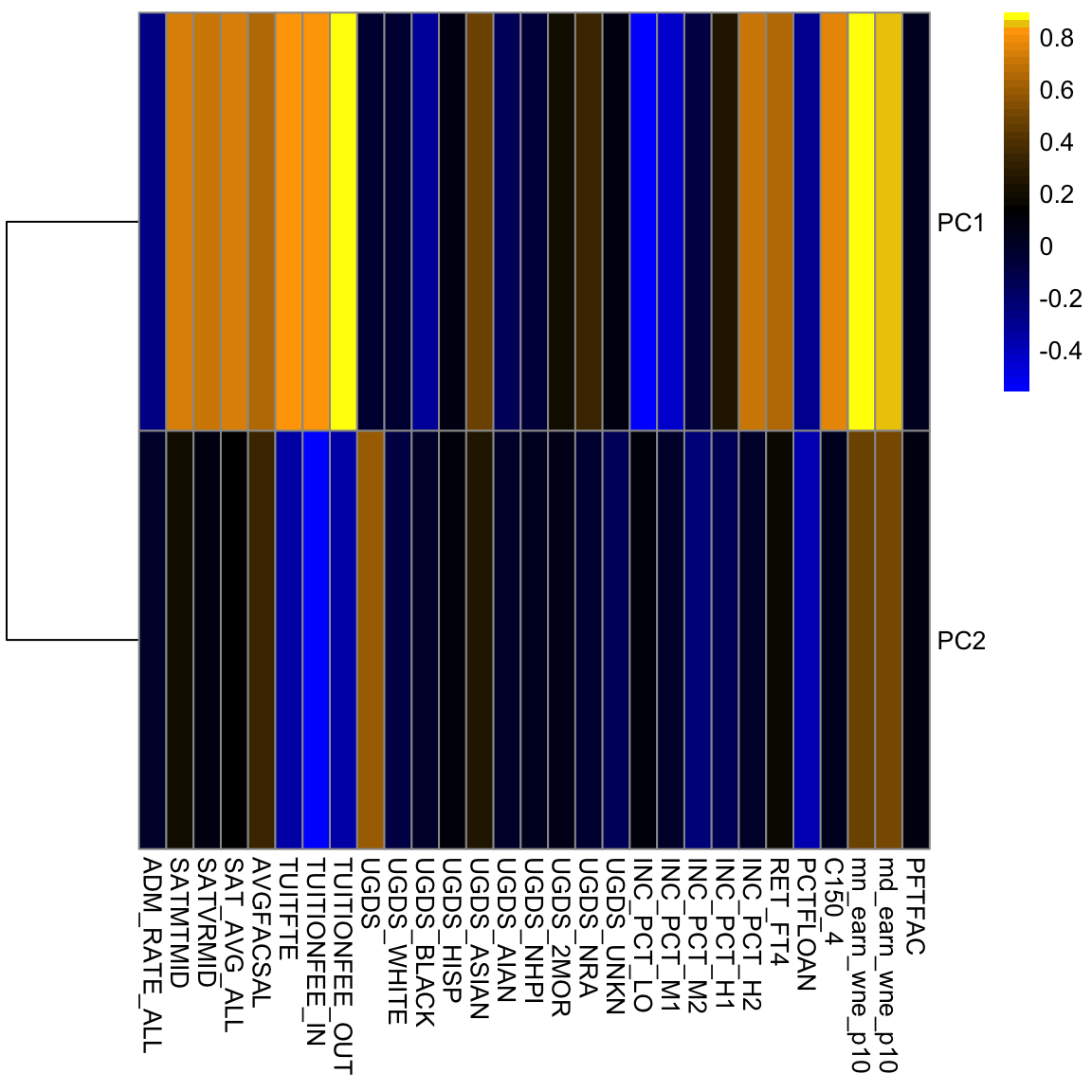
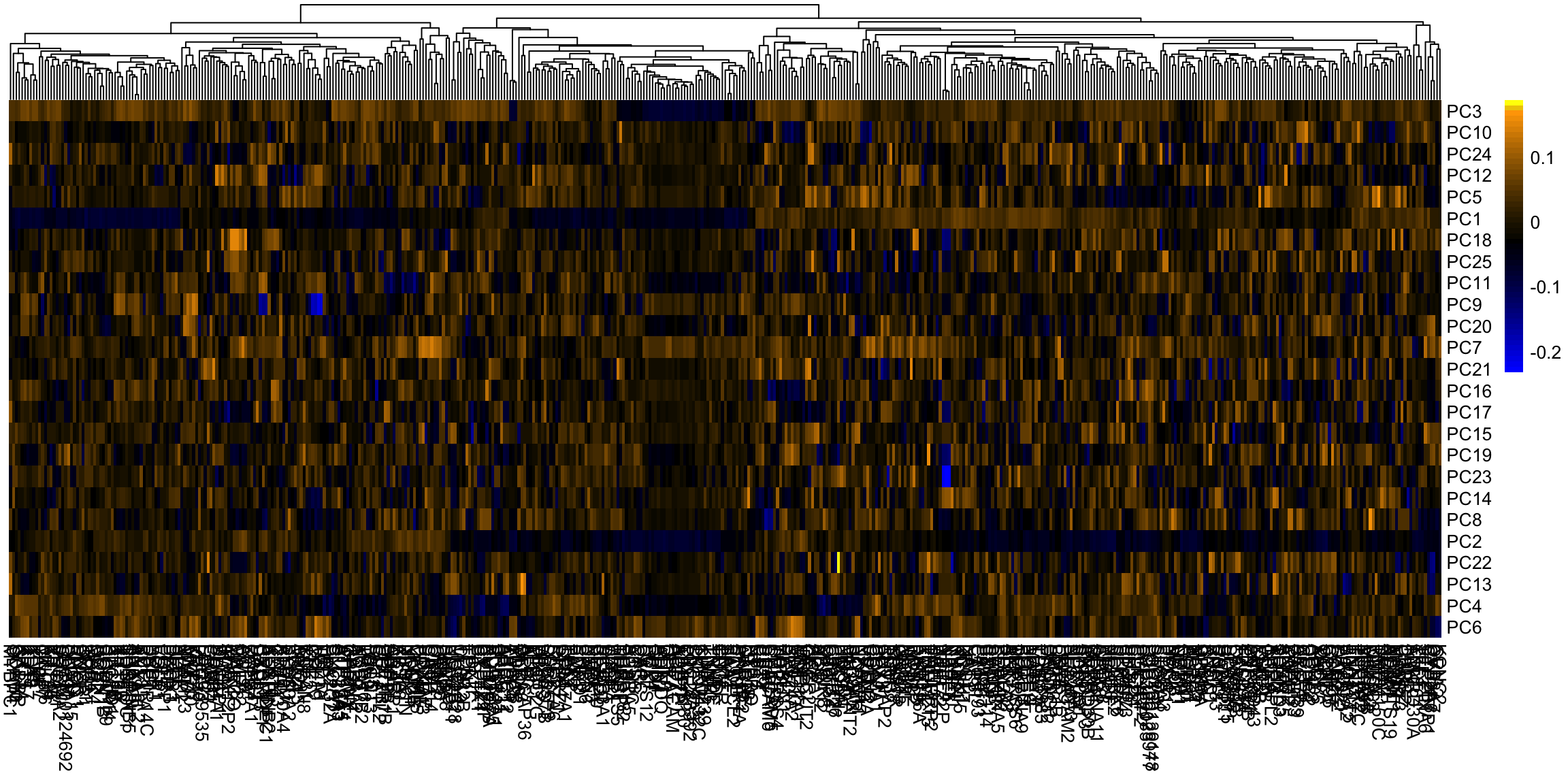
This is a very different set of coordinates for the points in 2 PCs. However, some of the same set of variables are still dominating, they are just different linear combinations of them (the two PCs lines are orthogonal to each other, but they can still just involve these variables because its such a high dimensional space). In these higher dimensions the geometry becomes less intuitive, and it can be helpful to go back to the interpretation of linear combinations of the original variables, because it is easy to scale that up in our minds. We can see this by a heatmap of all the coefficients. It’s also common to scale each set of PC coefficients by the standard deviation of the final variable \(z\) that the coefficients create. This makes later PCs not stand out so much.
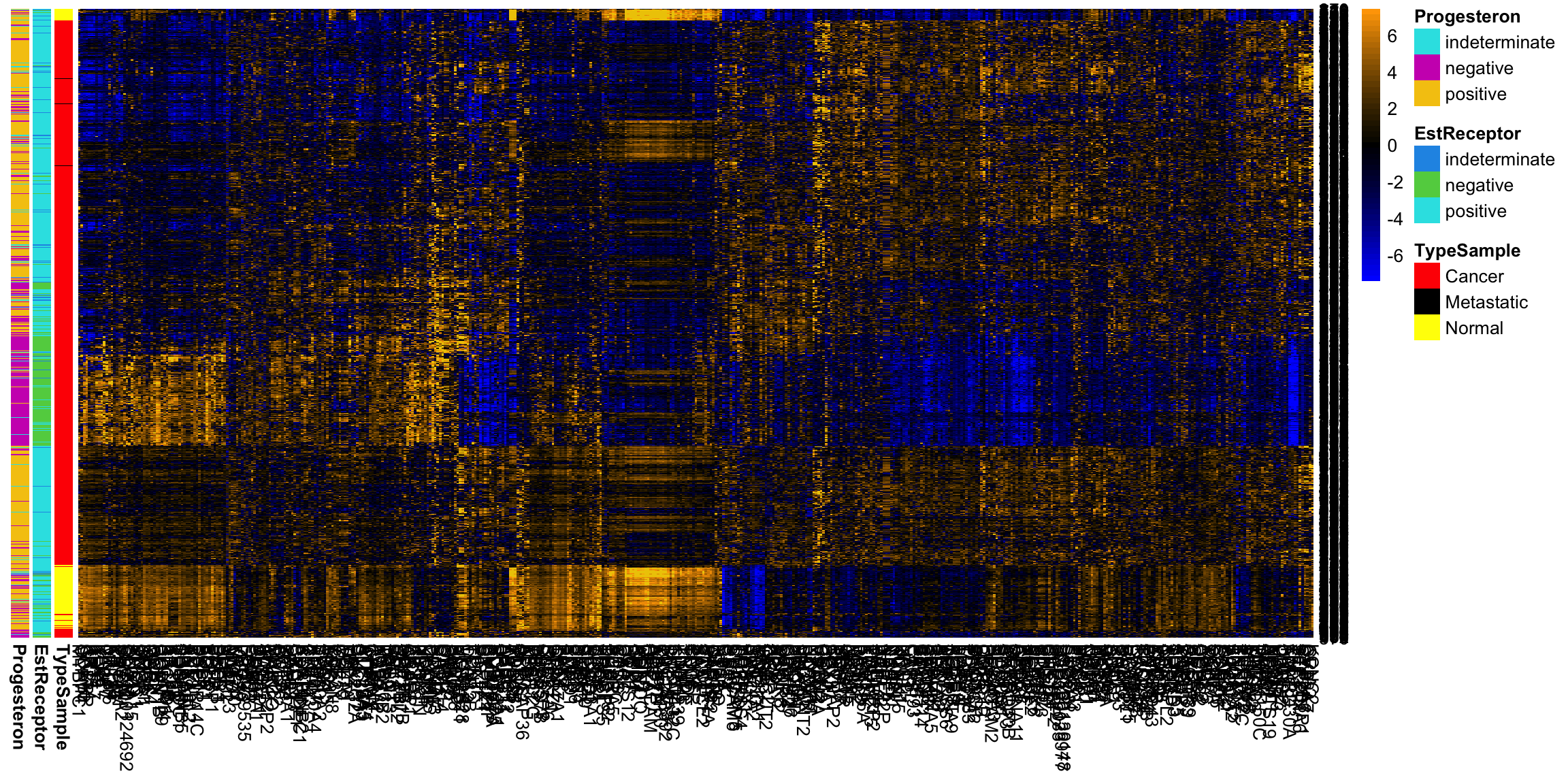
Breast data We can also look at the higher PCs from the breast data (with the normal samples).
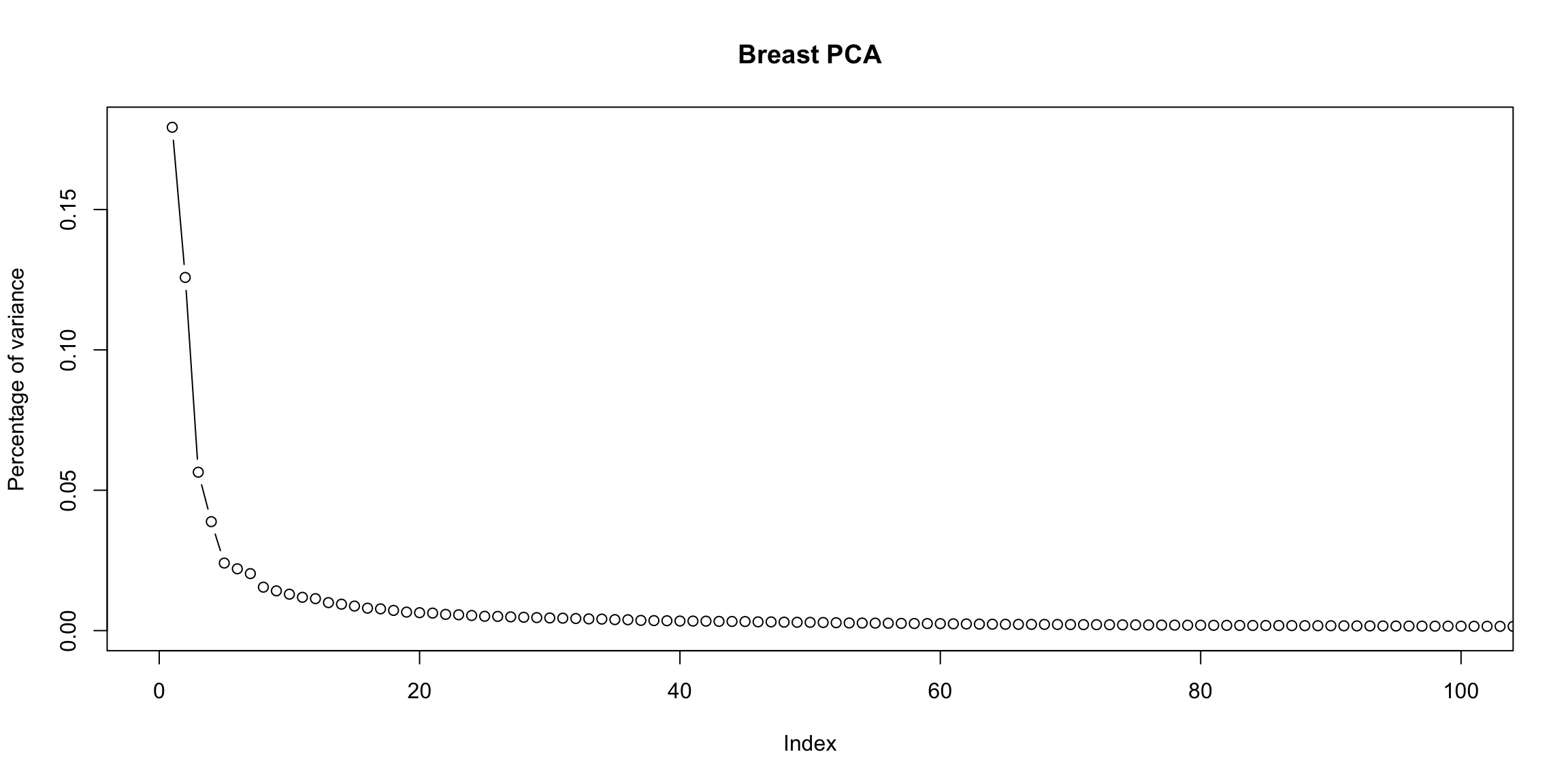
If there are 500 genes and 878 observations, how many PCs are there? We can see that there are distinct patterns in what genes/variables contribute to the final PCs (we plot only the top 25 PCs). However, it’s rather hard to see, because there are large values in later PCs that mask the pattern.
This is an example of why it is useful to scale the variables by their variance
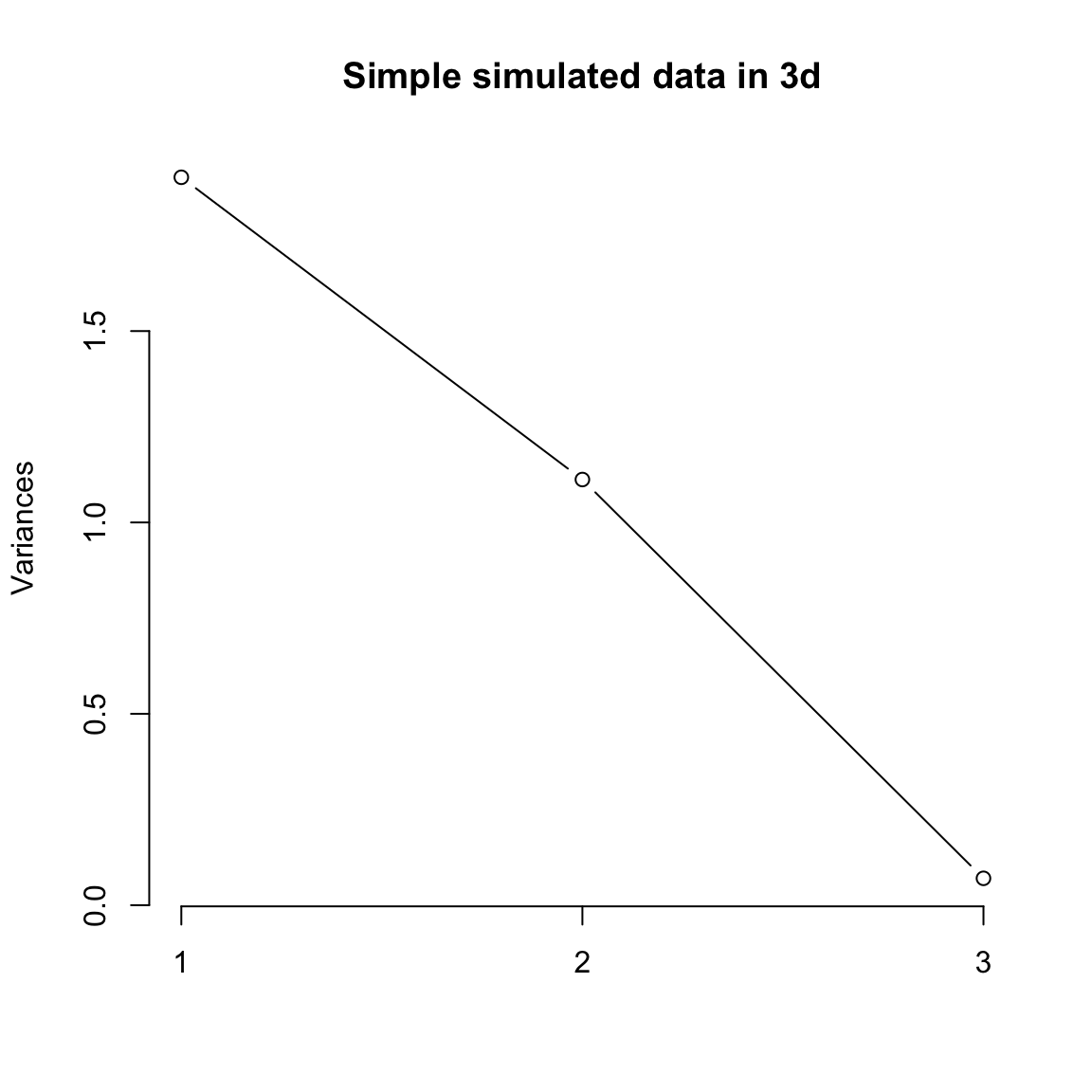
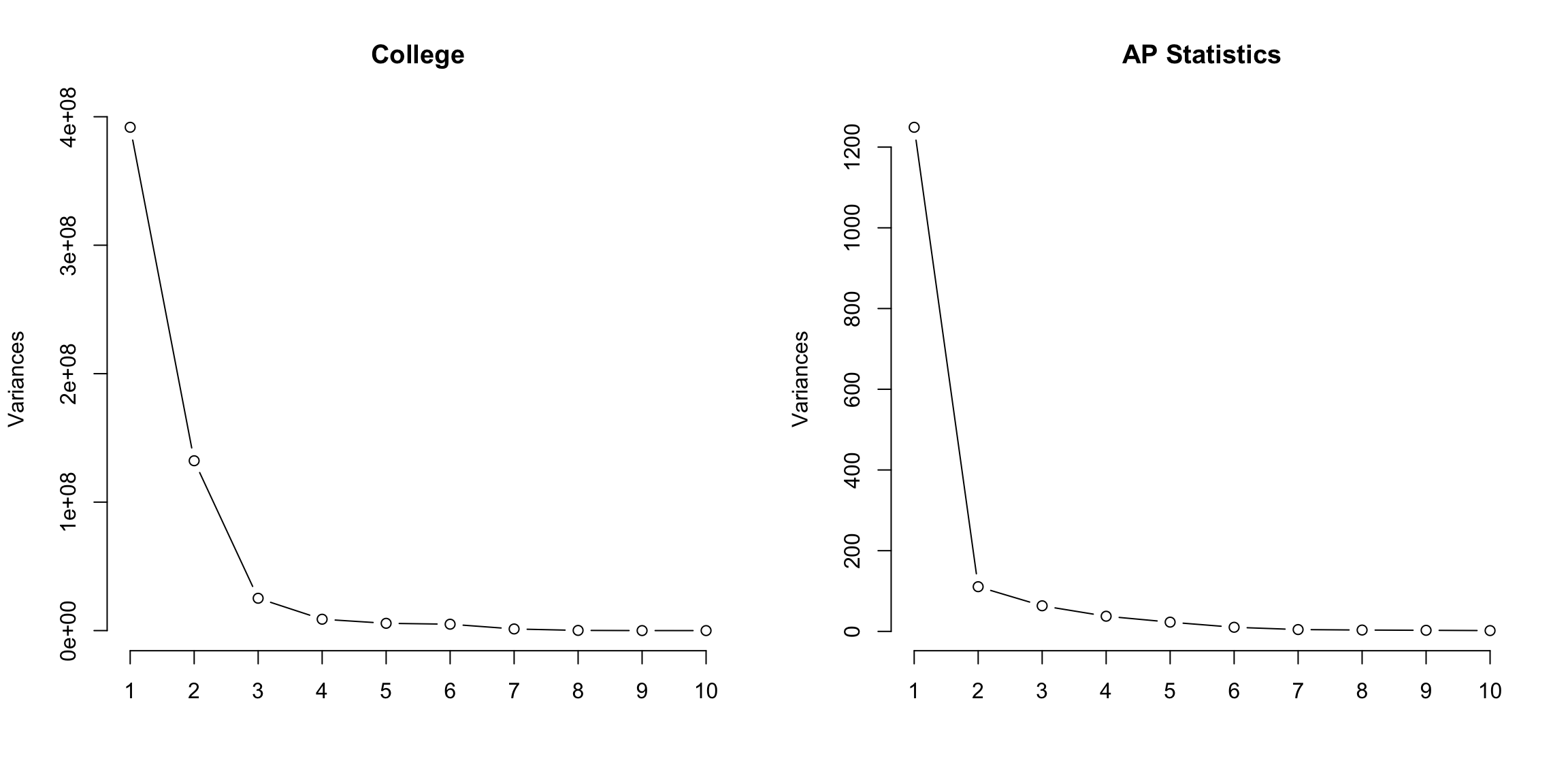
5.4.5 How many dimensions? If I can draw my data in 3d, then I can guess what is the right number of coordinates – not 1 but 2 in our toy example case were needed. When I have a lot of coordinates, like the college data, how can I possibly know? One technique is to look at how much variability there is in each of the coordinates – how much variance is there in the new variable created by each linear combination. If there’s not a lot of variability, then it indicates that when the points are projected onto that PC, they are huddled on top of each other, and its more likely to be noise than signal. Consider our simple simulation example, where there was more or less a plane describing the data. If we look at the variance in each set of linear combinations we create, there is practically 0 left in the last variable, meaning that most of the representation of the points is captured in two dimensions. This is a measure of how much we are “missing” by ignoring a coordinate.
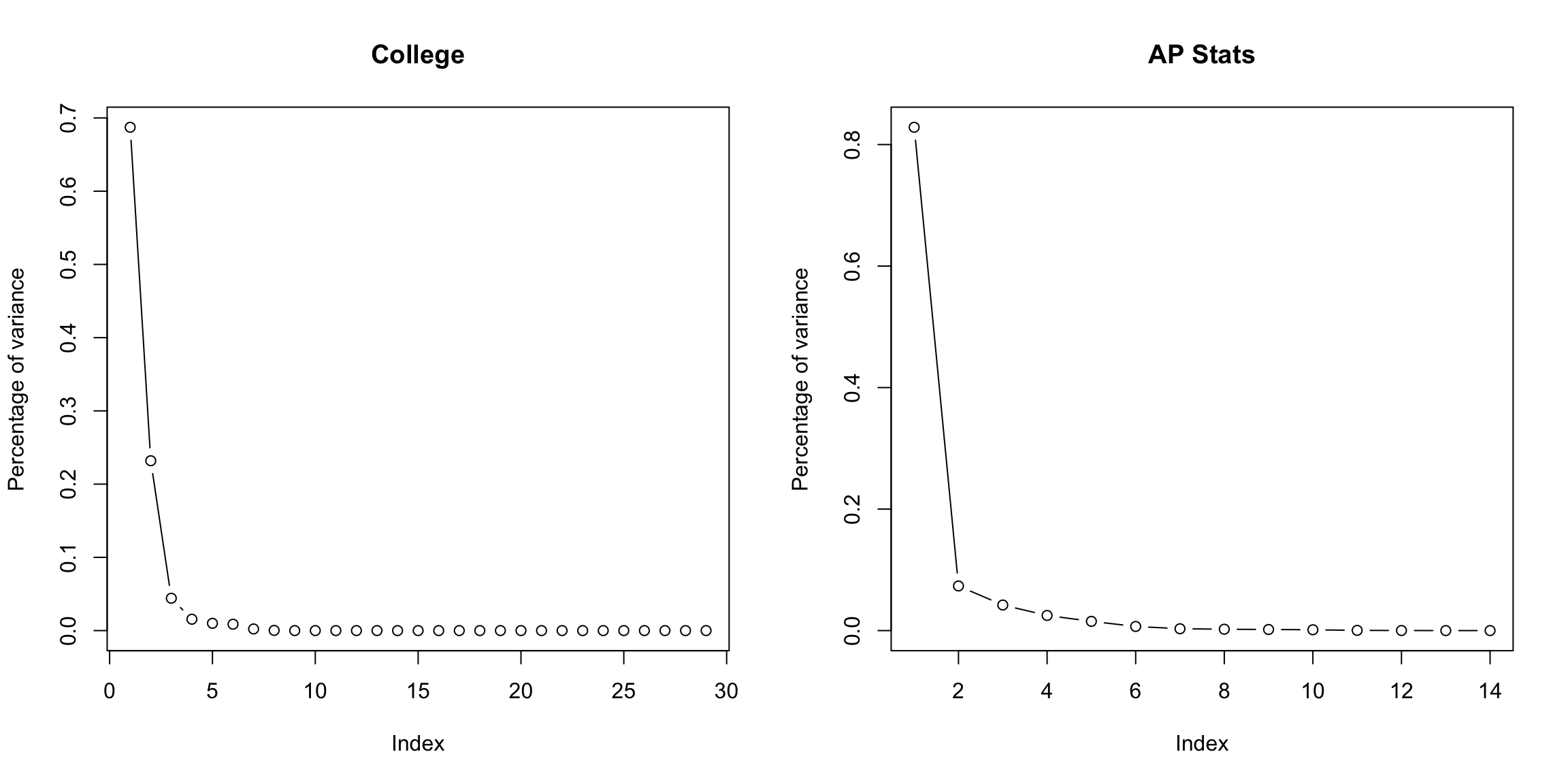
For the college data, we similarly see that the first two dimensions both have much larger amounts compared to other dimensions. The AP Statistics data is strongly in just the first dimension.
We can also plot this a percentage
2 dimensions is not always the answer It is just a happenstance of this data that 1-2 dimensions is summarizing the data. There is nothing magical about two dimensions, other than the fact that they are easy to plot! Looking at the top two dimensions can be misleading if there is a lot of additional variability in the other dimensions (in this case, it can be helpful to look at visualizations like pairs plots on the principal components to get an idea of what you might be missing.) We can do a similar plot for the breast cancer data.
What does this tell you about the PCA? (责任编辑:) |