|
超逼真对话型文字转语音软件Dia-1.6B免安装一键启动整合包下载 2025-05-25 分类:AI音频 评论(0) 本次分享一个刚出的超逼真对话型文字转语音软件Dia-1.6B,皇冠这个TTS软件不像传统的文字转语音那样,Dia可以生成对话音频,还可以生成非语言音效,如笑声,咳嗽,清嗓子等,还支持声音克隆。我基于当前Dia最新版本制作了免安装一键启动整合包。
文章目录
1 Dia-1.6B介绍 2 Dia-1.6B一键启动整合包使用说明 3 注意事项 4 对话型文字转语音软件Dia下载链接
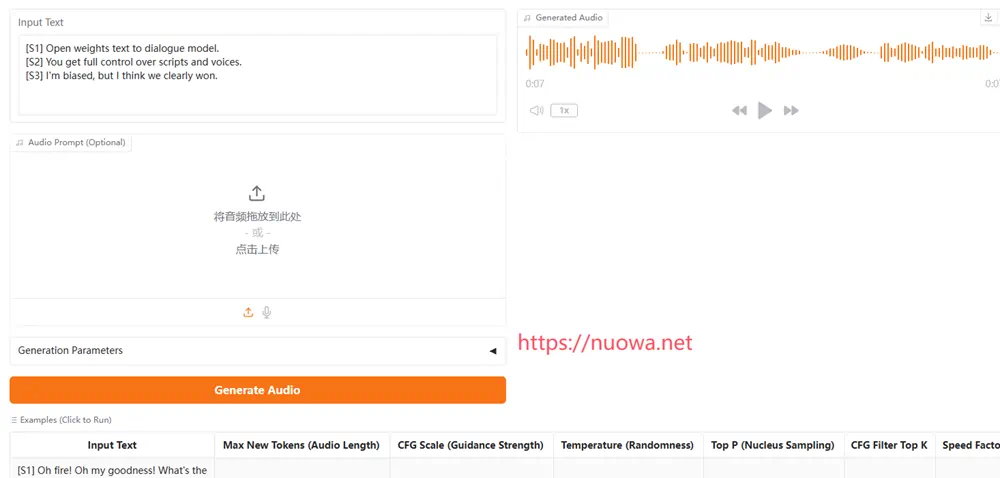
能够一次性生成超逼真对话的 TTS 模型。 使用场景 内容创作与媒体制作 影视配音:快速生成带情感变化的多角色对话音频,节省80%传统录音时间。 多语言版本:结合翻译API实现“剧本→翻译→配音”自动化流程。 教育科技 互动课件:生成历史人物对话或外语情景教学素材,增强学习沉浸感。 无障碍支持:为视障用户转化教材为情感化语音内容。 企业服务与客服 智能客服:生成带语气变化的应答语音,DG游戏提升交互自然度。 商业演示:输入PPT讲稿自动生成带停顿、重音的解说音频。 游戏与虚拟交互 动态NPC对话:实现游戏角色基于剧情的情感反馈,增强玩家体验。 Dia-1.6B一键启动整合包使用说明首先将网盘内的软件压缩包下载到本地电脑上并解压。然后双击启动软件.exe启动。 软件成功启动后会自动打开webUI界面。 在Input Text里输入对话文本,[S1]开头,就是人物1,后面跟说话内容。然后再跟[S2],就是人物2,依次交替。 Audio Prompt里可以上传5-10秒的音频用于音色克隆,也可以忽略。 点击下方的Generate Audio按钮开始生成音频。 默认使用GPU处理,耗时由英伟达显卡配置决定。 下面Generation Parameters里还有一些参数设置,欧博注册感兴趣的可以自行调节测试。 注意: 保持输入文本长度适中 短输入(相当于 5 秒以下的音频)听起来会不自然 非常长的输入(相当于超过 20 秒的音频)会使语音不自然地快。 请谨慎使用非语言标签,过度使用或使用未列出的非语言标签可能会导致奇怪的问题。 始终以[S1]开始输入文本,并始终在[S1]和[S2]之间交替(不要[S1]…[S1]…) 使用音频提示(语音克隆)时,请仔细遵循以下说明: 在生成文本之前提供待克隆音频的文字记录。 成绩单必须正确使用[S1]、[S2]发言者标签(即单个发言者:[S1]…、两个发言者:[S1]…… [S2]) 为了获得最佳效果,待克隆音频的时长应为 5 到 10 秒。(请注意:1 秒 ≈ 86 个 token) 将[S1]或[S2](倒数第二个说话者的标签)放在音频末尾,以提高结尾的音频质量 软件暂时以英语合成为主,还不能生成中文语音。 非语言音效代码: (laughs), (clears throat), (sighs), (gasps), (coughs), (singing), (sings), (mumbles), (beep), (groans), (sniffs), (claps), (screams), (inhales), (exhales), (applause), (burps), (humming), (sneezes), (chuckle), (whistles) 视频教程及效果演示:https://nuowa.net/1912 注意事项英伟达显卡显存6G可用,但是速度略慢,建议英伟达显存更高电脑使用 支持英伟达50系列显卡 使用前请将英伟达显卡驱动更新到最新版本 只支持Windows 10或11 软件运行路径中不要有非英文字符和空格,欧博代理待处理文件素材也要注意 对话型文字转语音软件Dia下载链接此内容仅限VIP查看,请先登录 可通过每日签到获得积分兑换VIP
可灵AI限时福利速度领取>> 软件催更及1对1人工答疑支持: https://nuowa.net/1806 软件无法使用?点击查看常见问题说明>> 分享到 上一篇Stable3DGen图片转3D模型软件本地电脑安装部署教程及注意问题 下一篇 对话型文字转语音软件Dia-1.6B本地电脑安装部署教程 相关推荐 最近更新
YuE:开放的全曲音乐生成基础模型,可免费一键生成完整歌曲,AI作曲,AI演唱,是一个高质量的AI音乐生成软件。我制作了最新的面安装一键启动整合包。 YuE介绍 YuE 是一系列突破性的开源基础模型,专为音乐生成而设计,欧博官网尤其适用于将歌词转化... 2025-06-10AI音频
可灵AI发福利了,通过专属优惠邀请码 6BZPEJK83JZ9 可额外获得50%灵感值。 现在图片、音乐、视频等等,啥都可以用AI生成,可灵AI就是快手旗下非常强大的一个AI内容创作平台,功能多样,效果强大。我最近半年几乎每周都会使用多次,... 2025-06-08羊毛
CSM是发布不久的一款多人对话语音生成模型,声音自然延迟低,同时支持克隆音色语音合成,我基于当前最新版本制作了免安装一键启动整合包。 Sesame CSM介绍 CSM(Conversational Speech Model) 是由... 2025-06-04AI音频
OpenManus是另一款AI自动化任务执行软件,是Manus的开源实现,无需邀请码,本地运行,我基于当前最新版本制作了免安装一键启动整合包。 OpenManus介绍 OpenManus 是一个开源复刻版 AI 智能体框架,由 MetaGP... 2025-06-04AI文本
OWL 是由 CAMEL-AI 团队开发的开源多智能体协作框架,旨在通过动态智能体交互实现复杂任务的自动化处理,在 GAIA 基准测试中以 69.09 分位列开源框架榜首,被誉为“Manus 的开源平替”。我基于当前最新... 2025-06-03AI文本
本次和大家分享另一个微软发布的非常热门的文件文档转Markdown格式文档的软件markitdown,软件可以将PDF,word,ppt,Excel等十几种格式文档转换为markdown格式文档,我基于当前最新0.1.2版本制作了免安装一键... 2025-06-02AI文本
本次和大家分享一个英伟达联合其他大学开发的一款应用describe-anything,该应用可以通过AI识别分析并详细描述图片视频中指定区域物体内容,我基于最新版制作了免安装一键启动整合包。 describe-anything介绍 Desc... 2025-05-29AI文本
又一款AI歌曲创作利器:ACE-Step,ACE-Step是刚发布不久的AI自动谱曲AI自动演唱软件,软件在歌曲生成速度、音乐连贯性和可控性上相对同类软件有了较大提升。ACE-Step在3小时前刚发布了新版本,我基于当前最新版本制作了免安装... 2025-05-26AI音频
本次分享一个刚出的超逼真对话型文字转语音软件Dia-1.6B,这个TTS软件不像传统的文字转语音那样,Dia可以生成对话音频,还可以生成非语言音效,如笑声,咳嗽,清嗓子等,还支持声音克隆。我基于当前Dia最新版本制作了免安装一键启动整合包。... 2025-05-25AI音频
本次和大家分享另一个非常牛叉的图片转3D模型软件Stable3DGen,从官方演示对比来看,效果要好于我之前分享的腾讯混元3D和TRELLIS,精度更高更细腻。基于当前最新版本我制作了一键启动整合包。 Stable3DGen介绍 随着从二维... 2025-05-22AI绘画 (责任编辑:) |